
import numpy as np
# Wipe all outputs from this notebook
from IPython.display import Image, clear_output, display
clear_output(True)
# Import local plotting functions and in-notebook display functions
import matplotlib.pyplot as plt
%matplotlib inline
Eigensystems as dominant “stretching” directions¶
The Spectral theorem states that if a matrix is Hermitian (, including real-symmetric), then: (1) The eigenvectors are an orthogonal basis, and (2) the eigenvalues are real. This is consistent with our intuition from the dynamical systems view: A “blob” of initial conditions gets anisotropically stretched at different rates along different directions. Eigenvalues are thus invariant to rotations (ie, multiplication by an orthonormal matrix)
Why are Hermitian matrices so important?¶
Many physical systems arise from the minimization of a scalar potential, such as a free energy or loss function. The dynamics of such systems are described by the gradient of the potential,
The Jacobian matrix of partial derivatives determines the local geometry and concavity of this scalar field, and thus stability and acceleration along various directions
Dynamical systems (continuous or discrete ) always have a Jacobian, but they do not necessarily have a corresponding scalar potential, which requires that the Jacobian be Hermitian.
The loss function in machine learning. Often in machine learning, we need to compare to datapoints, or to compare a high-dimensional model prediction to some ground truth value. If we have two vectors , a loss function or distance function assigns a scalar value to the pair,
The gradient of the loss function with respect to vector describes how much the loss function changes as we make small changes to the prediction along each dimension.
For example, we often seek to minimize the mean squared error or Euclidean distance between a vector of predictions and a vector of ground truth values ,
The gradient of the loss function with respect to is then the signed element-wise difference between the two vectors,
def random_points_disk(n, r=1):
"""Generate n random points within a disk of radius r"""
theta = np.random.uniform(0, 2 * np.pi, n)
r = np.sqrt(np.random.uniform(0, r**2, n)) # notice the sqrt
x, y = r * np.cos(theta), r * np.sin(theta)
return np.vstack((x, y)).T
pts = np.array(random_points_disk(1000))
plt.figure(figsize=(5, 5))
plt.scatter(pts[:,0], pts[:,1])
plt.axis('equal')
plt.title("Points before linear transformation")
# # Define a random linear transformation
np.random.seed(0)
A = np.random.uniform(-1, 1, size=(2, 2)) # random 2x2 matrix with entries in [-1, 1]
A = A + A.T # symmetrize matrix to make it Hermitian
# # Apply the transformation
pts = pts @ A
plt.figure(figsize=(5,5))
plt.scatter(pts[:,0], pts[:,1])
plt.axis('equal')
plt.title("Points after linear transformation - iteration 1")
# # Apply the transformation again
pts = pts @ A
plt.figure(figsize=(5,5))
plt.scatter(pts[:,0], pts[:,1])
plt.axis('equal')
plt.title("Points after linear transformation - iteration 2")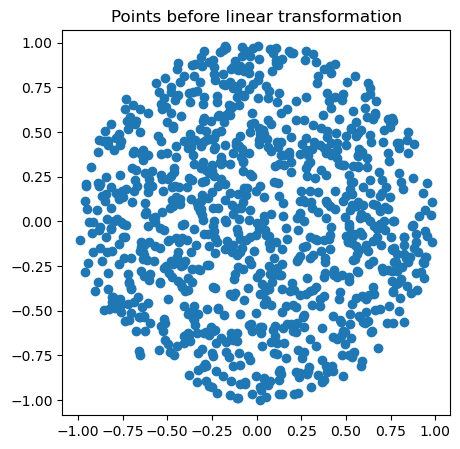
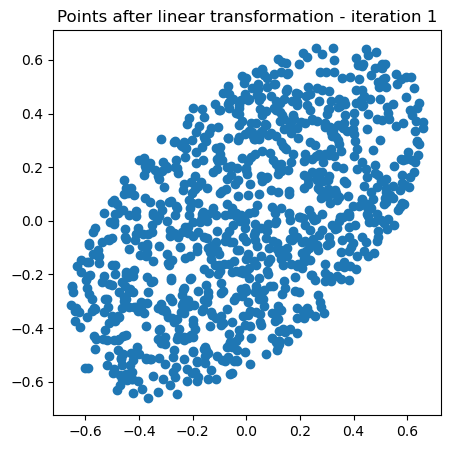
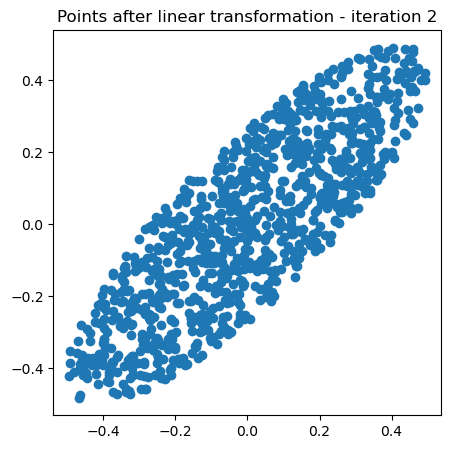
Now let’s repeat that iteration many times. We will apply our random Hermitian matrix many times to a cloud of points, and plot the result each time.
pts = np.array(random_points_disk(1000))
all_pts = [np.copy(pts)]
for _ in range(10):
pts = pts @ A
all_pts.append(np.copy(pts))
eig_vals, eig_vecs = np.linalg.eig(A)
total_scale = eig_vals[0]**10
plt.figure(figsize=(5,5))
plt.plot(pts[:, 0] / total_scale, pts[:, 1] / total_scale, '.')
plt.axis('equal')
plt.title("Point cloud after many applications of a random matrix")
plt.xlabel("x1")
plt.ylabel("x2")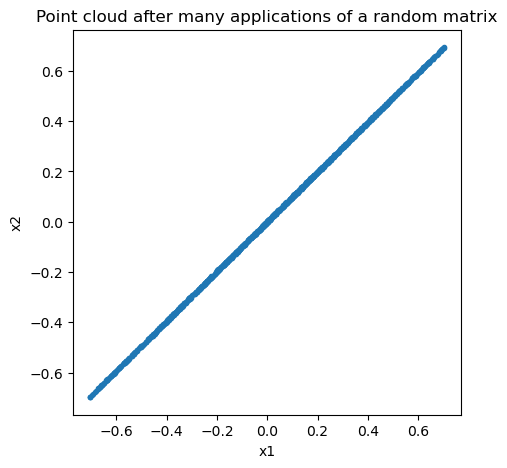
We can now plot the eigenvectors of , which are the directions along which the cloud is stretched.
eig_vals, eig_vecs = np.linalg.eig(A)
plt.figure(figsize=(5,5))
plt.plot(pts[:, 0] / total_scale, pts[:, 1] / total_scale, '.')
plt.axis('equal')
eig_vec1 = eig_vecs[:, 0]
eig_vec2 = eig_vecs[:, 1]
plt.plot([0, eig_vec1[0]], [0, eig_vec1[1]], 'r', lw=2, label="Eigenvector 1")
plt.plot([0, eig_vec2[0]], [0, eig_vec2[1]], 'k', lw=2, label="Eigenvector 2")
plt.legend()
plt.title("Points after many linear transformations, scaled")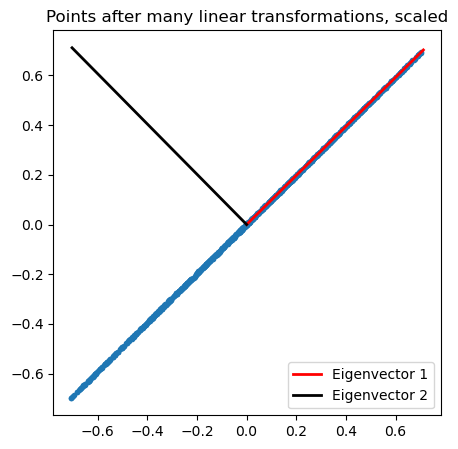
We can see that the eigenvectors of a Hermitian matrix indeed determine the dominant stretching directions of the cloud. What about the eigenvalues? To understand their role, we can project the point cloud onto the unit vectors associated with the eigenvectors of . Given our point cloud at a given time , , we can project it onto the unit vector by taking the dot product :
where are the row and column indices of . We can plot the maximum projection of the point cloud onto each eigenvector as a function of time, in order to measure the span of the point cloud along each eigenvector direction. We can compare this sequence to the geometric series of eigenvalues associated with each eigenvector, .
plt.figure(figsize=(8, 6))
plt.plot(np.max(np.array(all_pts) @ eig_vec1, axis=-1), '.r', label="Eigenvector 1")
plt.plot(np.max(np.array(all_pts) @ eig_vec2, axis=-1), '.b', label="Eigenvector 2")
plt.legend()
plt.title("Max span of cloud along eigenvector directions vs. iteration")
plt.plot(np.exp(np.log(eig_vals[0]) * np.arange(11)), color='r', label="Eigenvalue geometric series 1")
plt.plot(np.exp(np.log(-eig_vals[1]) * np.arange(11)), color='b', label="Eigenvalue geometric series 2")
plt.legend()
plt.xlabel("Iteration")
plt.ylabel("Max span")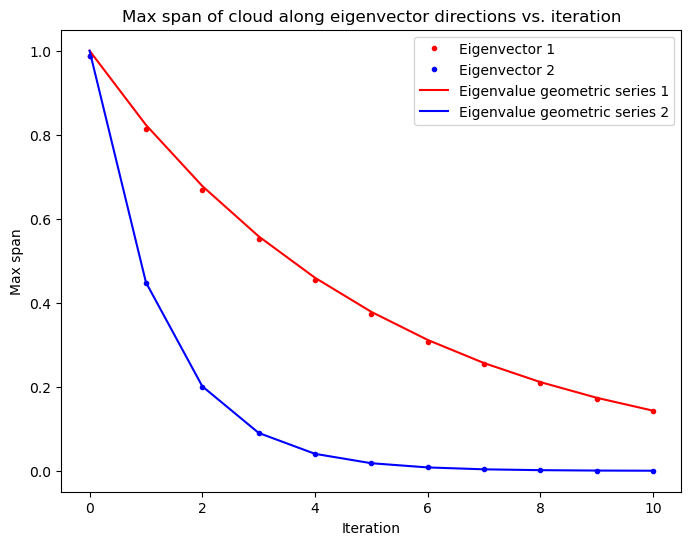
We can see that the eigenspectrum of Hermitian matrices has a straightforward interpretation, which is partially a consequence of the spectral theorem. The eigenvectors correspond to dominant stretching directions of a cloud of points under the action of a matrix, and the eigenvalues correspond to rates of compression or stretching per iteration. In the case of non-Hermitian matrices, we will observe rotation in addition to stretching, resulting in complex-valued eigenvalues and eigenvectors.
What about non-square matrices? Singular Value Decomposition¶
Suppose we have a matrix . For example, if we have a video of a fluid flow or sensor readings, we might have frames from sensors/pixels in each frame. If describes an algebraic system, we might have equations and unknowns, which can be overdetermined () or underdetermined ().
However, we can instead calculate the eigenspectrum of the square matrices or . We refer to the eigenvectors as the “right” or “left” singular vectors, respectively, and their associated eigenvalues are called the singular values. For an matrix, we have right singular vectors and left singular vectors.
Note that, when is square, and share the same eigenvalues. To see this, let be an eigenvector of with corresponding eigenvalue . . Consequently, is also an eigenvalue of with corresponding eigenvector .
For a non-square , we can factorize as
where the columns of are the right singular vectors, the columns of are the left singular vectors, and is a square diagonal matrix. The non-zero entries of are the square roots of the non-zero eigenvalues of or . Since the eigenvalues and eigenvectors can be listed in any order, by convention we normally list the elements in descending order of eigenvalue magnitude, .
The singular vectors decompose a dataset into characteristic directions in rowspace (left eigenvectors) and characteristic directions in columnspace (right eigenvectors).Importantly, unlike traditional eigenvalue decomposition, SVD applies to non-square matrices. Depending on the context, the singular vectors have different interpretations, including (1) Geometric, (2) Dynamical, (3) Data compression, pattern discovery
See image below from Chris Rycroft’s AM205 class

The singular values are the square roots of the eigenvalues of either or . Because or are both symmetric matrices, the spectral theorem ensures that the singular values are always real and non-negative, and so are usually indexed so that they are listed in descending order, .
The left singular vectors are the eigenvectors of . They are orthogonal unit vectors. The right singular vectors are the eigenvectors of . They are preimages of the vectors, so that . They are also orthogonal unit vectors.
Truncated versus full SVD¶
In full SVD, we calculate all singular values and vectors, and the matrices and are square with dimensions and , respectively, while the matrix is rectangular with dimensions . In truncated SVD, we calculate only the first singular values and vectors associated with the largest singular values ,
We define the truncated matrices of size , of size . still has size . The truncated SVD often approximates the original matrix well, making it useful for data compression and dimensionality reduction.
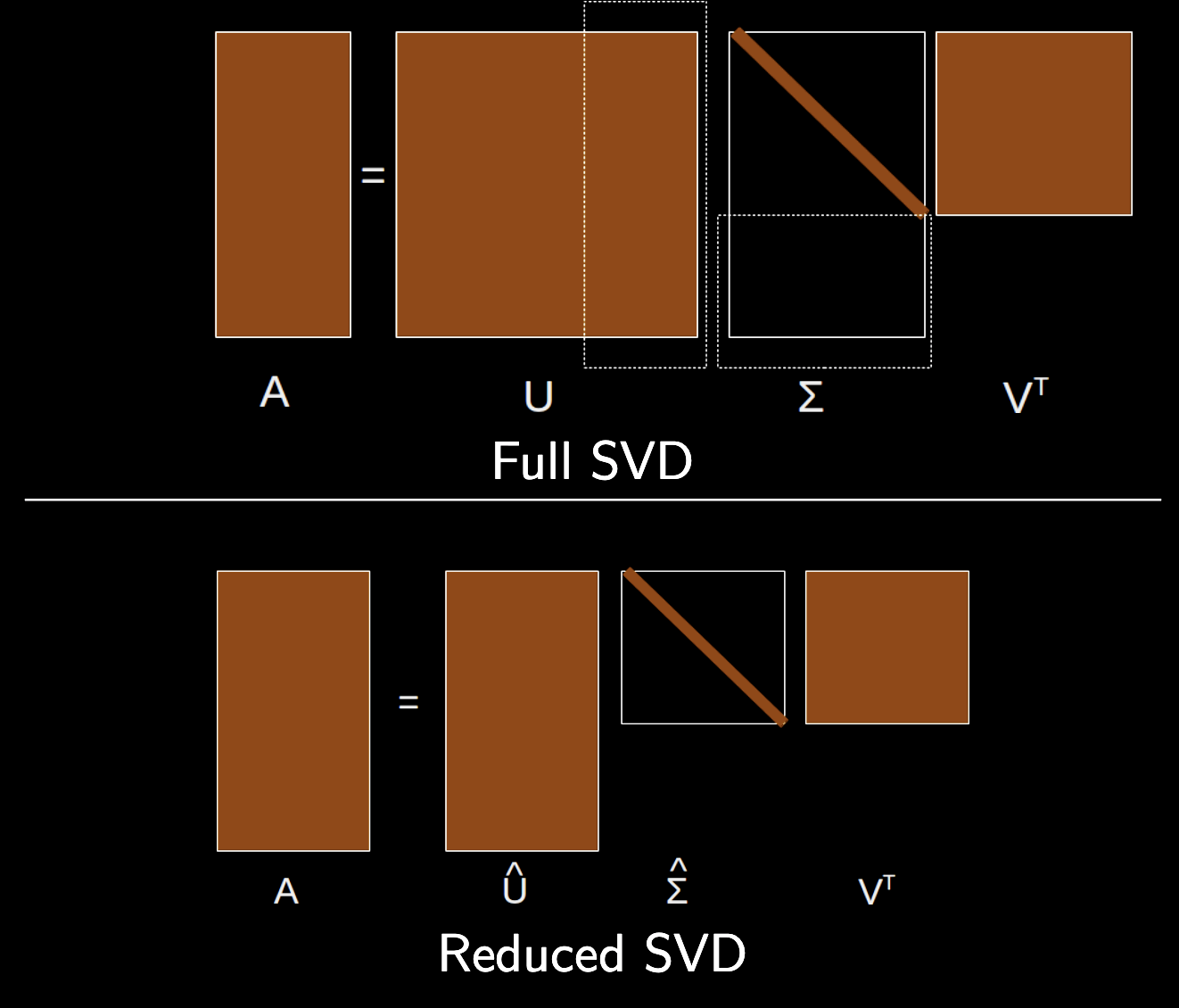
Image from from Chris Rycroft’s AM205 class
Dynamical systems interpretation of SVD¶
In dynamical systems, we might have skew-product structure, where the dynamics of some variables depend only on a subset of the others
Examples: is a a time like variable, is a random number generator (like we saw for the Ornstein-Uhlenbeck simulation); is a periodic driver.
Can write this system has rectangular structure $$
=
Can't use function '$' in math mode at position 146: …he sequence of $̲z_t$ values. No…
Our analogy to square matrix dynamics is now a bit more involved, because we can't iterate the system repeatedly without knowing the sequence of $z_t$ values. Notice that if the coupling to the $z$ driver system is zero, then our square "response" subsystem represents an autonomous linear system with Hermitian structure: $x$ affects $y$ as much as $y$ affects $x$,=
$$
When , we cannot do any spectral analysis anymore, because our coefficient matrix . However, we can instead analyze the two square matrices and . This is like analyzing two iterations of a square dynamical system.
a_response = np.array([[4, 1], [1, 2]]).T
print("Two iterations of square response subsystem without driving:")
print(a_response @ a_response.T, end='\n\n')
# print(a_response.T @ a_response, end='\n\n')
# Decoupled limit
a_full = np.array([[4, 1, 0], [1, 2, 0]]).T
print("Left matrix product with zero driving:")
print(a_full @ a_full.T, end='\n\n')
# print(a_full.T @ a_full, end='\n\n')
# Coupled limit
print("Left matrix product with driving:")
a_full = np.array([[4, 1, 3], [1, 2, 2]]).T
print(a_full @ a_full.T, end='\n\n')
Two iterations of square response subsystem without driving:
[[17 6]
[ 6 5]]
Left matrix product with zero driving:
[[17 6 0]
[ 6 5 0]
[ 0 0 0]]
Left matrix product with driving:
[[17 6 14]
[ 6 5 7]
[14 7 13]]
Loosely, the left matrix represents the propagation of an impulse in across the response subsystem (coupling of dynamical variables to the driver. This tells us about the dependence of response variables on earlier values
a_response = np.array([[4, 1], [1, 2]]).T
print("Two iterations of transpose of square response subsystem without driving:")
print(a_response.T @ a_response, end='\n\n')
# print(a_response.T @ a_response, end='\n\n')
# Decoupled limit
a_full = np.array([[4, 1, 0], [1, 2, 0]]).T
print("Right matrix product with zero driving:")
print(a_full.T @ a_full, end='\n\n')
# print(a_full.T @ a_full, end='\n\n')
# Coupled limit
print("Right matrix product with driving:")
a_full = np.array([[4, 1, 3], [1, 2, 2]]).T
print(a_full.T @ a_full, end='\n\n')Two iterations of transpose of square response subsystem without driving:
[[17 6]
[ 6 5]]
Right matrix product with zero driving:
[[17 6]
[ 6 5]]
Right matrix product with driving:
[[26 12]
[12 9]]
Loosely, the right matrix tells us about the driver system. If the driver couplings have the form , then the right matrix is perturbed by elementwise-adding the structured matrix to the right matrix. The diagonal elements tell us something about how much the different dynamical variables are affected. This interpretation is reminiscent of the density matrix of mixed quantum systems.
bias = np.array([2, 3])[:, None]
print(bias @ bias.T, end='\n\n')[[4 6]
[6 9]]
print(a_full.T @ a_full - a_response.T @ a_response, end='\n\n')[[9 6]
[6 4]]
Data representation and compression views¶
We consider the case where is a data matrix, describing observations of an dimensional process. Examples include a video ( is number of frames, is number of pixels), or a collection of points in space (). The left eigenvectors give characteristic “modes” in the data; they have the same dimensionality. The right eigenvectors give us the characteristic “loadings” onto those modes. SVD can thusbe used to reduce the dimensionality of a problem by truncating relevant eigenvalues; a basic compression method for high-dimensional data. The decay of the singular values provides a clue into the intrinsic dimensionality of the underlying data generating process.
Application: Image compression¶
The SVD of an image can be used to compress the image by truncating the sum over singular values and vectors. Recall that the SVD of a matrix is given by
We can verify that this decomposition is valid by reconstructing the original matrix from its SVD components.
from PIL import Image as img
## Local import to open the image
# im = img.open("../resources/hank.png")
## Fetch image from online hosting
import requests
from io import BytesIO
url = "https://raw.githubusercontent.com/williamgilpin/cphy/main/resources/hank.png"
response = requests.get(url)
im = img.open(BytesIO(response.content))
# convert to a numpy image using just the red channel
im = np.array(im)[..., 0]
print("Image shape is", im.shape)
plt.imshow(im, cmap='gray')
plt.axis('off');Image shape is (372, 248)

Numpy’s SVD solver returns the matrices . We use a keyword argument full_matrices=False to request reduced SVD, which returns with shape , with shape , and with shape . We can convert the vector to a diagonal matrix using the np.diag function.
Note that Numpy returns directly, and so we do not need to transpose it when we compute the reconstruction.
# Perform SVD on the image
U, s, V = np.linalg.svd(im, full_matrices=False)
sigma = s * np.eye(len(s))
# im = U @ sigma @ V.T
# im = U @ np.diag(s) @ V.T
print("U shape is", U.shape)
print("s shape is", s.shape)
print("V shape is", V.shape)
plt.imshow(U @ np.diag(s) @ V, cmap='gray')
plt.axis('off');U shape is (372, 248)
s shape is (248,)
V shape is (248, 248)
plt.imshow(U @ np.diag(s) @ V, cmap='gray')
SVD applies to any rectangular matrix. If corresponds to an image, we can reconstruct individual images by treating them as collections of columns, and reconstructing by adding together subsets of characteristic columns,
We can also truncate this sum at some in order to approximate the matrix instead.
If the singular values decay rapidly, then we can approximate the matrix by truncating this sum to the first terms
Us = U[:, :50]
ss = np.diag(s[:50])
Vs = V[:50, :]
print("Us shape is", Us.shape)
print("ss shape is", ss.shape)
print("Vs shape is", Vs.shape)
im_approx = Us @ ss @ Vs
print("Approximation shape is", im_approx.shape)
plt.imshow(im_approx, cmap='gray')
plt.axis('off');Us shape is (372, 50)
ss shape is (50, 50)
Vs shape is (50, 248)
Approximation shape is (372, 248)

We can now try varying the number of terms that we retain in the sum, and see how well we can reconstruct the original image.

from matplotlib.animation import FuncAnimation
from IPython.display import HTML
# Assuming frames is a numpy array with shape (num_frames, height, width)
# frames = np.array(model.history).copy()
fig = plt.figure(figsize=(6, 6))
img = plt.imshow(U[:, :1] @ np.diag(s[:1]) @ V[:1, :], vmin=np.min(im), vmax=np.max(im), cmap="gray");
plt.xticks([]); plt.yticks([])
# tight margins
plt.margins(0,0)
plt.gca().xaxis.set_major_locator(plt.NullLocator())
frames = [U[:, :i] @ np.diag(s[:i]) @ V[:i, :] for i in range(1, 60)]
def update(frame):
img.set_array(frame);
ani = FuncAnimation(fig, update, frames=frames, interval=50)
HTML(ani.to_jshtml())
We can directly look at the singular value distribution, to see if it matches our expectation based on the images.
plt.figure(figsize=(8, 5))
plt.semilogy(s)
plt.xlabel("Singular value index");
plt.ylabel("Singular magnitude");
plt.title("Singular values of Hank Hill");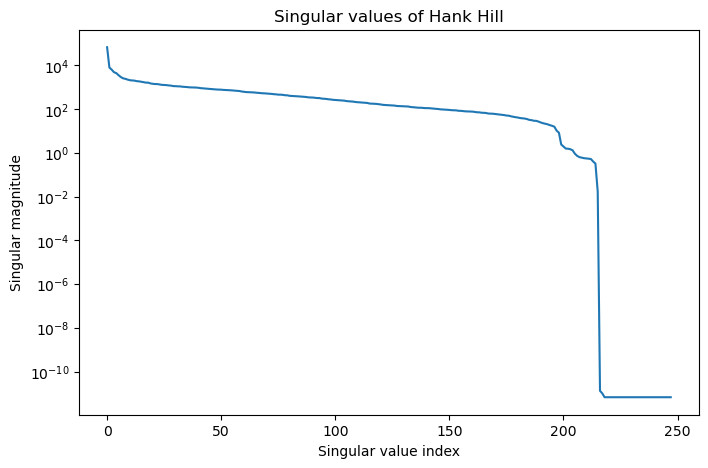
Density matrices and product states¶
From our image compression example, we can see that we can approximate a matrix by a sum over rank-1 (outer product) matrices
where the sum is over all singular values and vectors.
For a Hermitian matrix, , we can instead write this as a sum over rank-1 matrices with the same vector in both slots
where the are orthonormal eigenvectors and are the corresponding eigenvalues.
Recall that, in quantum mechanics, that if we have a system with “pure” eigenstates , then we can define the density matrix for a given mixed state as
We can see truncated SVD is equivalent to approximating by only including the most-probable terms with largest (up to a renormalization), thus removing rare states.
The Moore-Penrose pseudoinverse¶
Suppose we have an overdetermined system of equations
where , , and . If the number of rows is greater than the number of columns (), then we have more equations than unknowns, and the system is overdetermined. In this case, it is likely that no exists that satisfies exactly. However, we can instead seek the “best” solution in the sense of minimizing the squared error .
Deriving the pseudoinverse¶
We write the rectangular matrix in terms of its singular value decomposition
where, , , and . We multiply both sides by and note that , producing the equation
We next define the pseudoinverse of , denoted by , as the matrix with the same dimensions as that has the reciprocal of each non-zero element along the primary diagonal, and zeros everywhere else. Note that this pseudoinverse has a shape that is transposed relative to . This pseudoinverse has the property that . However, .
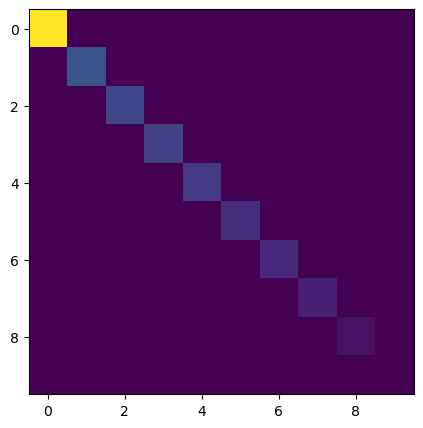
a = np.random.rand(10, 10)
## pad with zeros to make it rectangular
a = np.pad(a, ((0, 5), (0, 0)), mode='constant')
plt.figure(figsize=(5, 5))
plt.imshow(a)
u, s, v = np.linalg.svd(a)
s = np.diag(s)
plt.imshow(s)
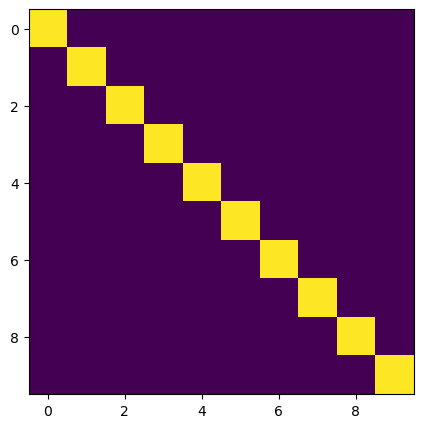
plt.figure(figsize=(5, 5))
plt.imshow(np.linalg.pinv(a) @ a)
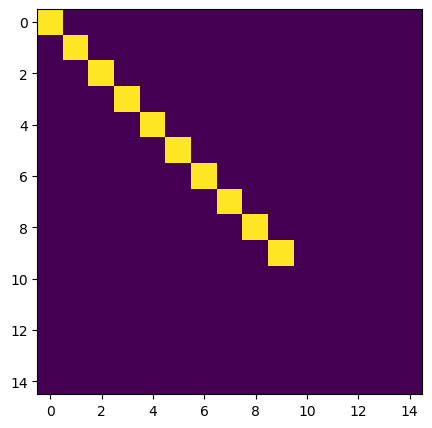
plt.figure(figsize=(5, 5))
plt.imshow(a @ np.linalg.pinv(a))
Our previous expression was
We multiply both sides of our expression above by to get
We can then multiply both sides by to get
We can then define the pseudoinverse of a rectangular matrix as
To understand the pseudoinverse, we consider the case where is greater than , so that is overdetermined.
# 1000 samples, 10 features
# 1000 equations/constraints, 10 unknowns
m, n = 15, 150
# m, n = 150, 15
A = np.random.normal(size=(m, n))
b = np.random.normal(size=(m, 1))
# A = np.random.normal(size=(15, 100))
# b = np.random.normal(size=(15, 1))
## Compute the Least Squares solution
def moore_penrose(A):
U, S, Vt = np.linalg.svd(A, full_matrices=False)
S_inv = np.zeros(S.shape)
# Calculate reciprocal of non-zero singular values
non_zero = S > 1e-15 # Identify non-zero singular values
S_inv[non_zero] = 1 / S[non_zero]
# Compute pseudoinverse
A_pseudo = Vt.T @ np.diag(S_inv) @ U.T
return A_pseudo
# A @ x = b
# A @ x - b
x = moore_penrose(A) @ b
Within the subspace associated with the columns of , the pseudotinverse is self-adjoint, and so .
plt.imshow(moore_penrose(A) @ A)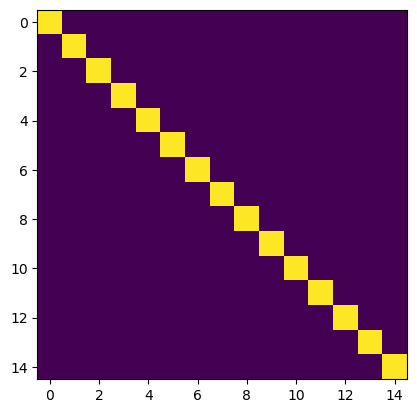
plt.plot(b, A @ x, '.') # plot the data---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[57], line 1
----> 1 plt.plot(b, A @ x, '.') # plot the data
ValueError: matmul: Input operand 1 has a mismatch in its core dimension 0, with gufunc signature (n?,k),(k,m?)->(n?,m?) (size 15 is different from 150)