Preamble: Run the cells below to import the necessary Python packages

import numpy as np
# Import local plotting functions and in-notebook display functions
import matplotlib.pyplot as plt
%matplotlib inline
Eigensystems¶
We can think of the “natural” coordinate system for a matrix as the set of eigenvectors. For Hermitian matrices, we can always rotate a collection of vectors, but the eigenspectrum gives us the dominant directions and scales associated with a bundle. Under a dynamical systems view, a “blob” of initial conditions gets anisotropically stretched along the eigendirections at different rates proportional to the eigenvalues.
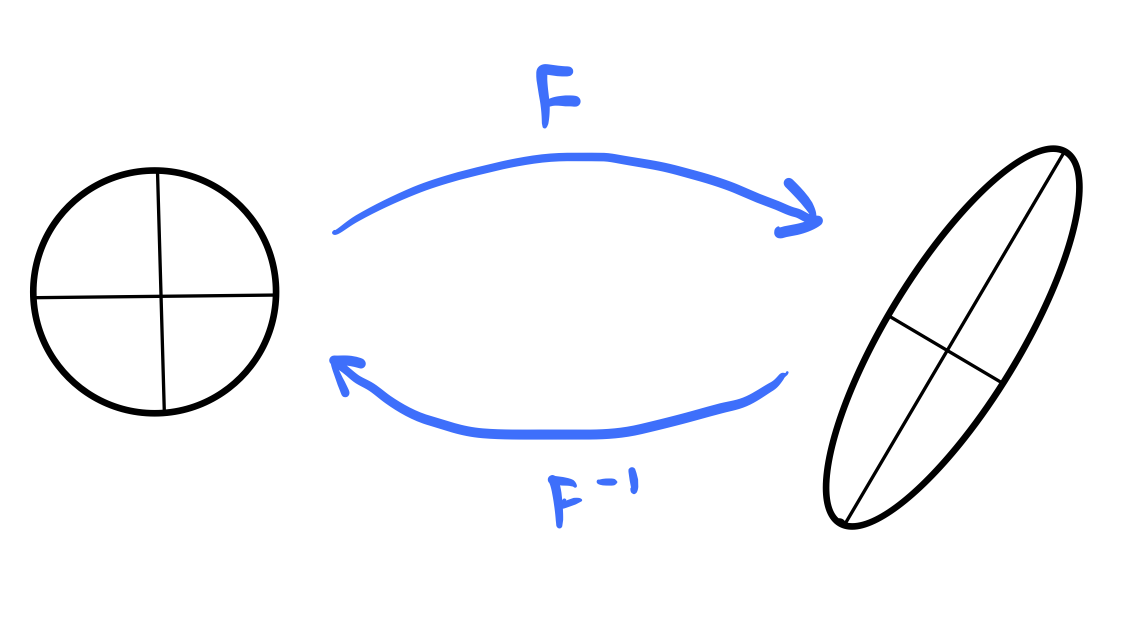
Finding eigenspectra is difficult for large matrices¶
Suppose we are given a square matrix . How can we find the eigenvalues and eigenvectors of this matrix numerically? The schoolyard method for performing this calculation consists of first solving the characteristic equation for the eigenvalues such that
Calculation of the determinant has runtime complexity , making computation of the characteristic polynomial itself no harder than matrix multiplication. However, the hard part is factoring the characteristic equation into a form amenable to finding the eigenvalues, . Since the polynomial has order , at large , it often becomes impractical to use numerical root-finding to solve the eigenvalue problem using schoolyard methods.
Iterative numerical linear algebra¶
Iterative numerical linear algebra methods are a class of algorithms that gradually build up a solution to a problem by making small changes to an initial guess. These methods are particularly useful for large matrices, where the schoolyard method for finding the eigenvalues and eigenvectors is too slow. They have more predictable time cost (complexity input agnostic), are easier to control precision/runtime, and potentially faster in cases with fast convergence. They are also easier to parallelize and can exploit sparsity.
However, they are also indirect and approximate, and so they don’t always converge to the exact solution. Bad starting conditions or ill-conditioning can lead to a large prefactor in the runtime to reach a given target accuracy.
QR Factorization and Gram Schmidt orthogonalization¶
Classical schoolyard methods for matrix inversion via Gauss-Jordan elimination could be summarized as a single matrix, the of LU factorization. The runtime complexity of this process is thus , which is the same as the runtime complexity of matrix multiplication.
In a similar vein, we can summarize the QR factorization and Gram-Schmidt orthogonalization as a single matrix, the and matrices of QR factorization. The runtime complexity of this process is thus also .
We will use Gram-Schmidt orthogonalization to build up an orthonormal basis from a bundle of vectors. Other orthogonalization methods (Givens rotations, Householder triangularization) exist as well.
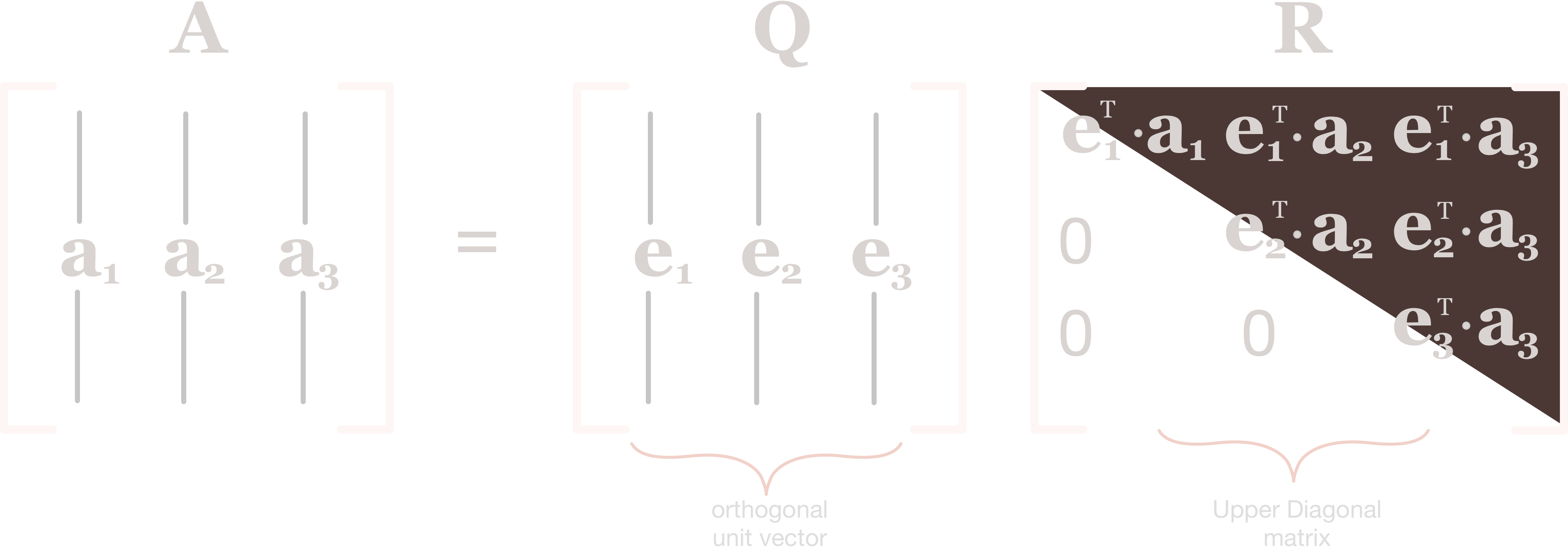
Image from Source
To illustrate the traditional Gram-Schmidt algorithm, we start by picking two vectors and and orthogonalizing them. We first pick one of the vectors, which we can call the “pivot” vector, and normalize it to get the first column of our orthonormal basis .
We then project the second vector onto the first vector and subtract the projection from the second vector to get the second column of .
## Sample and plot two random vectors
np.random.seed(10)
vec1, vec2 = np.random.rand(2), np.random.rand(2)
plt.figure(figsize=(6, 6))
plt.quiver(0, 0, vec1[0], vec1[1], angles='xy', scale_units='xy', scale=1, color='r', label="a1")
plt.quiver(0, 0, vec2[0], vec2[1], angles='xy', scale_units='xy', scale=1, color='b', label="a2")
plt.legend()
plt.xlim(-1, 1)
plt.ylim(-1, 1)
## Normalize the first vector
# vec1 = vec1 / np.linalg.norm(vec1)
# ## # Project vec2 onto vec1, and then scale vec1 by the ratio of the
# ## projection to the length of vec1
vec2_proj_onto_vec1 = np.dot(vec2, vec1) / np.dot(vec1, vec1) * vec1
# # # # # Subtract the projection from vec2
vec2_orth = vec2 - vec2_proj_onto_vec1
plt.figure(figsize=(6, 6))
# # Draw the projection, add a small offset to avoid overlapping vectors
plt.quiver(
0, 1e-2, vec2_proj_onto_vec1[0], vec2_proj_onto_vec1[1] + 1e-2,
angles='xy', scale_units='xy', scale=1, color='b', alpha=0.5)
# # # # Draw the orthogonalized vector
plt.quiver(0, 0, vec1[0], vec1[1], angles='xy', scale_units='xy', scale=1, color='r')
plt.quiver(0, 0, vec2_orth[0], vec2_orth[1], angles='xy', scale_units='xy', scale=1, color='b')
plt.xlim(-1, 1)
plt.ylim(-1, 1)
(-1.0, 1.0)
What if we wanted to invert this process? We can walk through the steps of the Gram-Schmidt process
are our starting vectors, and are our orthogonalized vectors.
We can recover the first vector by writing
We can recover the second vector by writing
We can therefore store the parenthetical scalar terms in their own matrix, , and write the above equations as
where .
# Create a matrix with vec1 and vec2 as columns
A = np.array([vec1, vec2]).T
# Normalize the "first" vector to get q1, the first unit vector
vec1_norm = np.linalg.norm(vec1)
q1 = vec1 / vec1_norm
# Normalize the orthogonal vector to get q2
vec2_orth_norm = np.linalg.norm(vec2_orth)
q2 = vec2_orth / vec2_orth_norm
# Construct the Q matrix, which is the matrix of unit vectors. The first column
# points in the same direction as vec1
Q = np.array([q1, q2]).T
# Construct the R matrix
R = np.zeros((2, 2))
R[0, 0] = vec1_norm
R[0, 1] = np.dot(q1, vec2)
R[1, 1] = vec2_orth_norm
# R is the matrix of projections onto the previous vectors
# R = np.array([[np.dot(vec1, vec1), np.dot(vec1, vec2)], [0, np.dot(vec2_orth, vec2_orth)]])
# Check that Q and R recreate A
# print('Q = \n', Q)
# print('R = \n', R)
# print('Q @ R = \n', Q @ R)
# print('A = \n', A)
## Check that Q and R recreate A
print(np.allclose(A, Q @ R))
# print(np.all(A == (Q @ R)))True
For non-square matrices, we might append extra orthogonal columns to and zeros to , so that now represents a full-rank matrix with rowsspace spanning its full columnspace
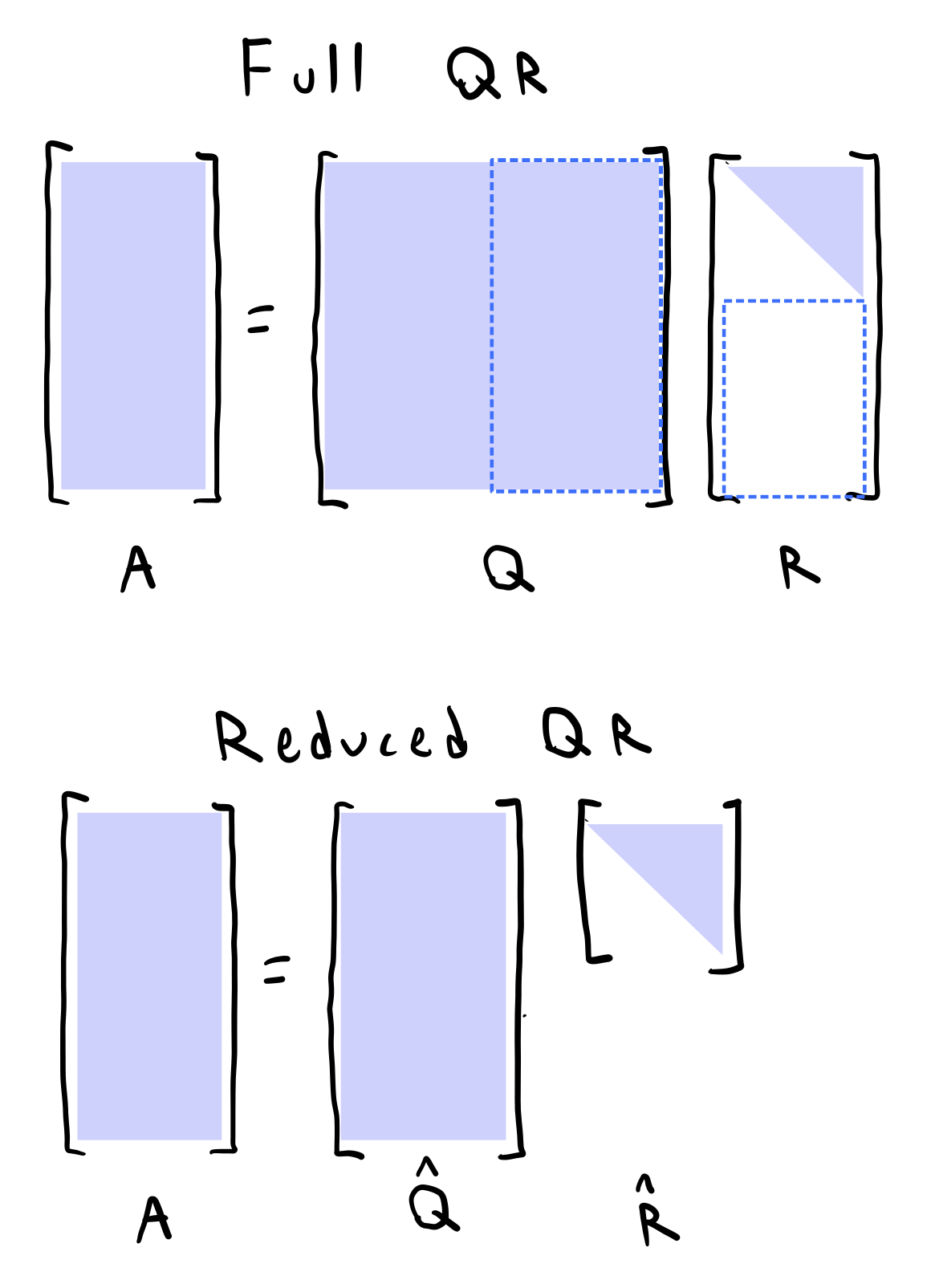
The classical Gram-Schmidt algorithm¶
Pick a column vector from the matrix and normalize it to have unit length. This will be the first column of the matrix . We will keep a running partial matrix, . After this step, . We store the normalization factor as well, .
Move to the next column vector of . Subtract the projection of onto from . Normalize the resulting vector to get the second column of .
We cache the projection factor, , as well as the normalization factor, .
Move to the third column vector of . Subtract the projection of onto and the projection of onto . Normalize the resulting vector to get the third column of . We can do this concisely by performing a single matrix-vector multiplication with the running partial matrix:
We cache the normalization factor, , but we also cache both projection factors,
Repeat steps 1 and 2 for the remaining columns of to build the full and matrices.
So. in traditional Gram-Schmidt, once we’ve passed a column and normalized it, we never touch it again. All future columns are orthogonalized with respect to the columns we’ve already processed. By the time we get to the last column of an matrix, we need to subtract projections from it to orthogonalize it.
def qr_factorization(X):
"""
Compute the QR factorization of a square matrix using iterative Gram-Schmidt
orthonormalization.
Args:
X (numpy.ndarray): A square matrix.
Returns:
Q (numpy.ndarray): An orthonormal matrix.
R (numpy.ndarray): The upper triangular matrix.
"""
X = X.T # want first index to be the column index (for convenience)
Qk = list()
R = np.zeros(X.shape) # Initialize an empty matrix to store projection factors
## Pick first vector as the "pivot" and normalize it
q1 = X[0] / np.linalg.norm(X[0])
Qk.append(q1) # Add the first vector to the list of Qk
## Project rest of the vectors onto the pivot to fill out the first column of Q
R[0, 0] = np.linalg.norm(X[0])
for i in range(1, X.shape[0]):
## Project the ith vector of X onto all previous vectors in Qk
qi = X[i] - np.sum(np.dot(X[i], np.array(Qk[:i]).T) * np.array(Qk[:i]).T, axis=-1)
R[i, i] = np.linalg.norm(qi) # store the normalization factor
## Normalize the orthogonalized vector
qi /= np.linalg.norm(qi)
## Update the upper triangular matrix R
R[i, :i] = np.dot(X[i], np.array(Qk[:i]).T)
## Add the orthogonalized vector to the list of Qk
Qk.append(qi)
## Transpose the Q and R matrices to get the correct format
Q, R = np.array(Qk).T, R.T
return Q, R
We can now test that our QR factorization is correct. We will use numpy’s built-in allclose function to check that the product of the Q and R matrices is equal to the original matrix to within some small tolerance.
A = np.random.normal(size=(40, 40))
q, r = qr_factorization(A)
np.allclose(A, q @ r)
# np.sum(np.abs((A - (q @ r))))Trueplt.imshow(q.T @ q)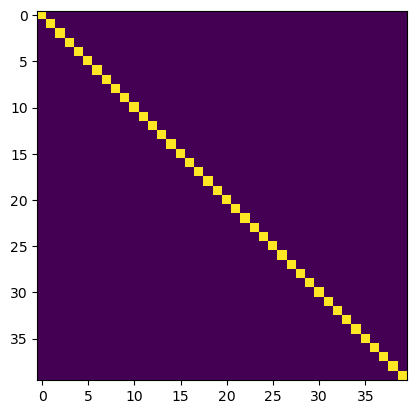
Eigenspectrum estimation via the QR eigenvalue method¶
How do we get the eigenspectrum of a matrix using QR factorization? Recall that rotating a matrix does not change its eigenvalues. The orthogonal basis returned by QR factorization is a rotation matrix, and so the eigenvalues of are the same as the eigenvalues of . Recall that, for orthogonal matrices, .
We can therefore repeatedly rotate the matrix using QR factorization until it becomes diagonal, in which case the diagonal entries are the eigenvalues of . We therefore have an iterative algorithm for computing the eigenvalues and eigenvectors of a symmetric matrix ,
We compute the QR factorization of to get and .
We then form a new matrix by reversing the order of multiplication of and . Since is a rotation matrix and is a triangular matrix, this new matrix has the same spectrum as
We accumulate the rotation matrix by multiplying the previous rotation matrix by
where . This will allow us to track the cumulative rotation of as we iterate.
We repeat steps 1-3 until the matrix is diagonalized. The eigenvalues are then given by the diagonal entries of , and the eigenvectors are given by the columns of .
Implementing the QR eigenvalue algorithm in Python¶
Here, we are going to implement the QR algorithm in Python. Note that numpy, as in other languages, uses row, column format for indexing. Since we often interpret a matrix as an array of column vectors, selecting the ith column vector of a matrix a has the form a[:, i]. By convention, eigenvectors are returned in a format where the columns are eigenvectors, and so we select individual eigenvectors along the second axis.
We can break our implementation into several stages:
Implementing QR factorization. We can use either the Gram-Schmidt algorithm or Householder reflections to compute the QR factorization.
Computing an eigensystem via repeated QR factorization and transformation
class QREigendecomposition:
"""
A numpy implementation of the QR eigenvalue algorithm for symmetric matrices
Attributes:
eigenvalues (numpy.ndarray): The eigenvalues of the matrix.
eigenvectors (numpy.ndarray): The eigenvectors of the matrix, stored as columns.
store_intermediate (bool): Whether to store the intermediate matrices.
"""
def __init__(self, store_intermediate=False):
self.eigenvalues = None
self.eigenvectors = None
self.store_intermediate = store_intermediate
def qr_factorization(self, X):
"""
Compute the QR factorization of a square matrix using Gram-Schmidt
orthonormalization.
Args:
X (numpy.ndarray): A square matrix.
Returns:
Q (numpy.ndarray): An orthonormal matrix.
R (numpy.ndarray): The upper triangular matrix.
"""
X = X.T # want first index to be the column index (for convenience)
q, r = np.zeros(X.shape), np.zeros(X.shape) # preallocate
q[0] = X[0] / np.linalg.norm(X[0])
r[0] = X @ q[0]
for i in range(1, X.shape[0]):
q[i] = X[i] - np.sum(np.dot(X[i], q[:i].T) * q[:i].T, axis=-1)
q[i] /= np.linalg.norm(q[i])
## Update the upper triangular matrix R
r[i, i:] = X[i:] @ q[i]
q = q.T # because we took transpose beforehand for easier indexing
return q, r
def find_eigensystem(self, X, max_iter=2000, tol=1e-6):
"""
Find the eigenvalues and eigenvectors of a matrix
Args:
X (numpy.ndarray): A square matrix.
max_iter (int): The maximum number of iterations to perform.
tol (float): The tolerance for convergence.
Returns:
eigenvalues (numpy.ndarray): The eigenvalues of the matrix.
"""
prev = np.copy(X)
tq = np.identity(X.shape[0])
if self.store_intermediate: self.intermediate = [np.copy(X)]
for i in range(max_iter):
q, r = self.qr_factorization(X)
X = r @ q # q^-1 x q
# X = X @ q
# np.matmul(r, q)
# np.dot(r.T, q)
# np.einsum('ij,jk->ik', r, q)
tq = tq @ q # accumulate the eigenvector matrix
if self.store_intermediate: self.intermediate.append(np.copy(X))
## Check for convergence and stop early if converged
if np.linalg.norm(X - prev) < tol:
break
prev = np.copy(X)
eigenvalues, eigenvectors = np.diag(X), tq
sort_inds = np.argsort(eigenvalues)
eigenvalues, eigenvectors = eigenvalues[sort_inds], eigenvectors[:, sort_inds]
self.eigenvalues, self.eigenvectors = eigenvalues, eigenvectors
return eigenvalues, eigenvectors
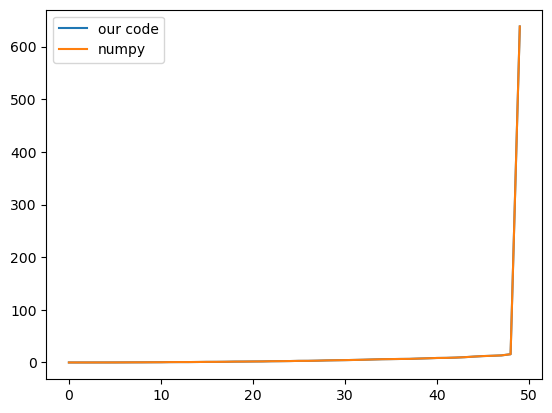
We can start by checking whether our QR factorization implementation finds the same eigenvalues as numpy’s built-in function.
a = np.random.random((50, 50))
a = a @ a.T # ensure symmetric
model = QREigendecomposition(store_intermediate=True)
eigenvalues, eigenvectors = model.find_eigensystem(a, max_iter=6000)
# plt.figure()
# plt.plot(eigenvalues, label="QR")
# plt.plot(np.linalg.eigh(a)[0], label="numpy")
# plt.legend()
plt.figure()
plt.plot(eigenvalues, label="our code")
plt.plot(np.linalg.eigh(a)[0], label="numpy")
plt.legend()
print(np.allclose(eigenvalues, np.linalg.eigh(a)[0]))
print(np.sum(np.abs(eigenvalues - np.linalg.eigh(a)[0])))False
6.29712135819156e-08
We can get a sense of why the QR algorithm works by plotting the intermediate matrices. Recall that those measure the projections of the current matrix onto the orthonormal basis . The off-diagonal elements of thus quantify the distance from orthogonality in the current basis. We can therefore calculate the norm of the off-diagonal elements of to see how quickly the algorithm converges as a function of the iteration .
all_r = [model.qr_factorization(X)[1] for X in model.intermediate]
plt.figure(figsize=(6, 4))
plt.semilogy([np.linalg.norm(R - np.diag(np.diag(R))) for R in all_r])
# plt.xlim(0, 60)
plt.xlabel("Iteration")
plt.ylabel("Norm of off-diagonal elements of $R_k$")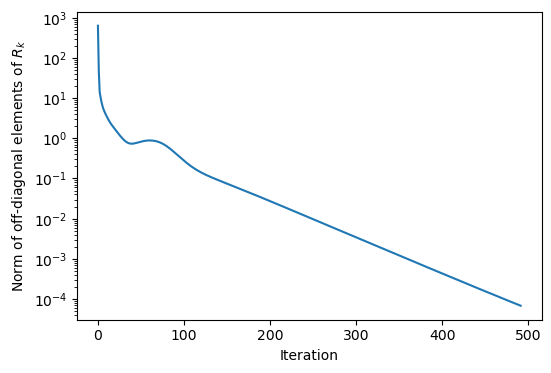
We can also visualize the matrix directly, to see this process in action.
plt.figure(figsize=(7, 7))
for i, r in enumerate(all_r[:16]):
plt.subplot(4, 4, i+1)
plt.imshow(r, vmin=np.percentile(all_r[0], 5), vmax=np.percentile(all_r[0], 95))
plt.xticks([]); plt.yticks([])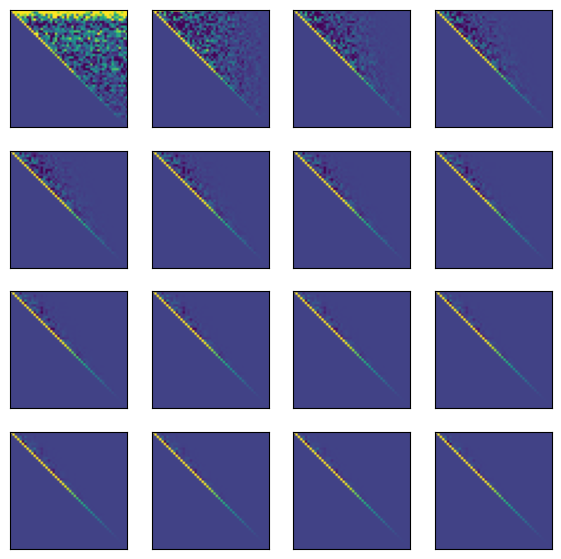
## Make a video of the intermediate $R_k$ matrices
from matplotlib.animation import FuncAnimation
from IPython.display import HTML
fig, ax = plt.subplots()
im = ax.imshow(all_r[0], vmin=np.percentile(all_r[0], 5), vmax=np.percentile(all_r[0], 95))
title = ax.set_title(f"R_0")
def update_frame(frame_idx):
im.set_data(all_r[frame_idx])
title.set_text(f"R_{frame_idx}")
return (im, title)
anim = FuncAnimation(fig, update_frame, frames=len(all_r[:50]), interval=200, blit=False)
html = HTML(anim.to_jshtml(default_mode="loop"))
plt.rcParams["animation.html"] = "jshtml" # use JS-based display (no ffmpeg needed)
plt.close(fig) # avoid a duplicate static figure
display(anim) # or: HTML(anim.to_jshtml(default_mode="loop"))
Why does this algorithm work?¶
For a full-rank matrix , we can always find an orthonormal matrix via QR factorization using a method such as Gram-Schmidt orthonormalization. The matrix represents the basis, and the upper-triangular matrix represents the weights necessary to project the original matrix into the orthogonal basis.
Recall that the eigenvalues of a matrix are invariant to changes in basis, and so the matrix acts like a rotation of the eigenvectors. When we perform the transformation , we are essentially calculating . This essentially represents a change of basis, which gradually aligns the columns of with the eigenvectors, resulting in an upper-triangular form where we can just read the eigenvalues off the diagonal.
Moreover, because a composition of rotations is still a rotation, but keeping track of the net rotation in the matrix , we can immediately read off the eigenbasis for the system.
For a more technical description of this algorithm, as well as explicit definition of the Gram-Schmidt orthonormalization process, we refer to Chapter 11 of William Press’s Numerical Recipes textbook, as well as these lecture notes by Peter Arbenz. It’s possible to generalize the QR algorithm to work for non-symmetric matrices with complex eigenvalues. However, this implementation is pretty subtle. A good discussion is provided in the Watkins textbook
# Let's do a simple unit test to make sure that our class is working as expected
import unittest
class TestQR(unittest.TestCase):
def test_factorization(self):
"""
Test that the QR factorization is correct
"""
np.random.seed(0)
a = np.random.random((20, 20))
model = QREigendecomposition()
q, r = model.qr_factorization(a)
self.assertTrue(np.allclose(a, q @ r), "QR factorization failed")
def test_eigenvalues(self):
"""
Test that the eigenvalues are correct against numpy's built-in function
"""
np.random.seed(0)
a = np.random.random((20, 20))
a = a @ a.T # make sure it's symmetric
model = QREigendecomposition()
eigenvalues, _ = model.find_eigensystem(a)
self.assertTrue(np.allclose(eigenvalues, np.linalg.eigh(a)[0]), "Eigenvalues are incorrect")
def test_eigenvectors(self):
"""
Test that the eigenvectors are correct against numpy's built-in function
"""
np.random.seed(0)
a = np.random.random((5, 5))
a = a @ a.T # make sure it's symmetric
model = QREigendecomposition()
_, eigenvectors = model.find_eigensystem(a)
## We have to take the absolute value of the eigenvectors because the eigenvectors
## are not unique up to a sign.
self.assertTrue(
np.allclose(np.abs(eigenvectors), np.abs(np.linalg.eigh(a)[1])),
"Eigenvector calculation failed"
)
unittest.main(argv=[''], exit=False)
...
----------------------------------------------------------------------
Ran 3 tests in 0.031s
OK
<unittest.main.TestProgram at 0x12e8ebe00>## Show the process of A becoming orthogonal
plt.figure(figsize=(9, 1))
for i, amat in enumerate(model.intermediate[:10]):
vec1, vec2 = amat[:, 0], amat[:, 1]
plt.subplot(1, 10, i+1)
plt.plot([0, vec1[0]], [0, vec1[1]], color='red')
plt.plot([0, vec2[0]], [0, vec2[1]], color='blue')
plt.xlim(-0.1, 1)
plt.ylim(-0.1, 1)
plt.axis('off')
Classical Gram-Schmidt struggles on ill-conditioned matrices¶
We will create a nearly-singular matrix by first defining a singular matrix, and then adding a small amount of noise to each column vector. We can then compute the QR factorization of the matrix, and see how close the product of the Q and R matrices is to the original matrix.
np.random.seed(0)
a = np.random.random(1000)
for epsilon in [1.0, 1e-14]:
aa = np.tile(a, (len(a), 1)).T + np.random.random(size=(len(a), len(a))) * epsilon
print("Condition number: ", np.linalg.cond(aa))
q, r = qr_factorization(aa)
print("Error: ", np.linalg.norm(q @ r - aa))
print("\n")Condition number: 4287360002.900908
Error: 3.102098429293163e-08
Condition number: inf
Error: 0.00023823491912506546
Idea: we want to start dis-aligning the column vectors as early as possible in the iterative algorithm¶
We know that ill-conditioning occurs when the column vectors are close to being parallel. We therefore want to start dis-aligning the column vectors as early as possible in the iterative algorithm. The moment we find a unit vector basis element, we immediately remove it from all of the remaining vectors in our set . Recall the curse of dimensionality: in higher dimensions, the condition number tends to be larger, and so the Gram-Schmidt process can be numerically unstable.
Another way to think about this: the Gram-Schmidt process is a series of projections. In traditional Gram-Schmidt in high-dimensions, we subtract from the last vector a bunch of very small terms (because the last vector will likely already be close to orthogonal to the previous vectors).
Modified Gram-Schmidt decomposition¶
We can mitigate the effect of nearly parallel column vectors by performing the projections and subtractions in a different order. To understand this, we will write out the first few steps of the Gram-Schmidt process for both the traditional and modified versions.
Traditional Gram-Schmidt
Pick the first column vector and normalize it to form the first unit vector
Project vector 2 onto vector 1, multiply by unit vector 1, and then subtract the resulting vector from vector 1
Normalize vector 2. Now move to the third column vector, then project to find its components along unit vector 1 AND unit vector 2, then subtract both
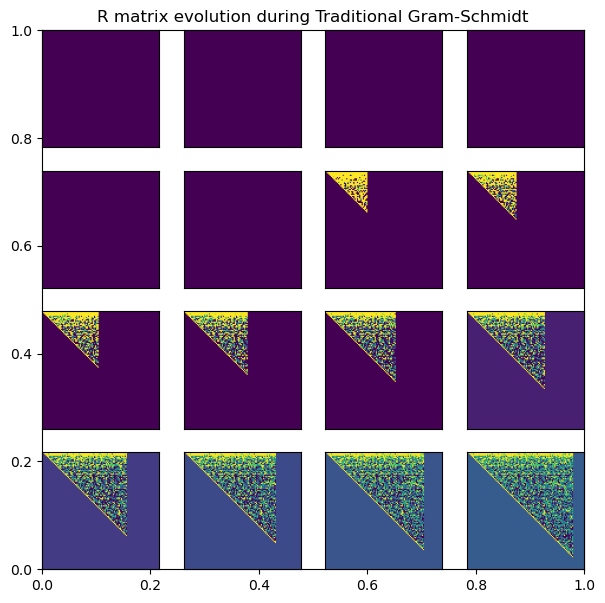
This approach becomes unstable in high-dimensions, because at later steps we are subtracting a large number of small terms. As a result, the elements of the residual vector can become very small before we apply the re-normalization step, leading to numerical errors. This motivates the modified Gram-Schmidt algorithm, in which we perform the steps in a different order, allowing us to re-normalize after each subtraction of a pair of vectors.
Modified Gram-Schmidt
Pick the first column vector and normalize it.
Pick all remaining column vectors, and subtract their projections onto the first column vector.
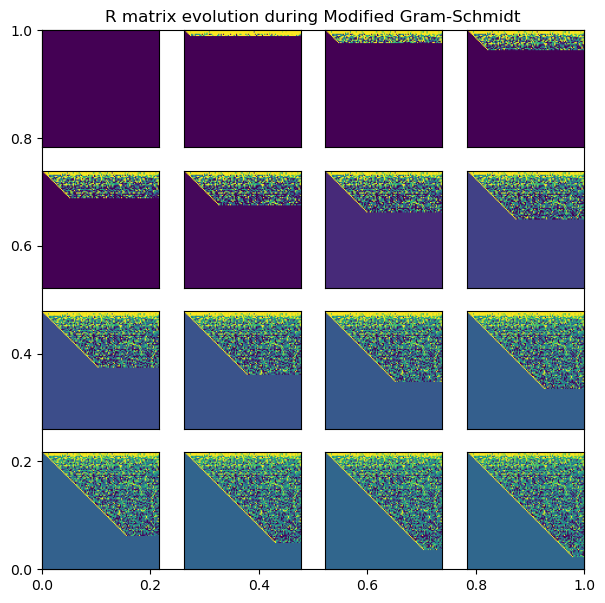
Besides the order in which we normalize and sweep, the key difference is the step where we compute projections between previously-determined unit-vectors. In the modified Gram-Schmidt, the projection occurs between the latest unit vector and a column vector where the previous unit vectors have already been subtracted out. As a result, our dot product is less likely to be very small, because all of the previous shared basis vectors have already been removed by the time we compute the dot product.
In general, numerical operations behave better when the involved vectors are further from parallel. Modified Gram-Schmidt sidesteps finding the dot product between two nearly-aligned vectors.
class QRFactorizationSolver:
"""
Solver a linear problem using preconditioning with QR factorization. Implements both
the traditional Gram-Schmidt process and the modified Gram-Schmidt process.
Attributes:
store_history (bool): Whether to store the history of the QR factorization.
history (list): A list of tuples containing the Q and R matrices at each iteration.
"""
def __init__(self, store_history=True):
self.store_history = store_history
if self.store_history:
self.history = []
def qr0(self, X):
"""
Perform QR factorization using classical Gram-Schmidt process.
"""
self.Q = np.copy(X) # Orthonormal vectors will be stored here
self.R = np.zeros_like(X, dtype=float)
## Store the initial guess
if self.store_history:
self.history.append([self.Q.copy(), self.R.copy()])
# Loop over column vectors
for i in range(X.shape[1]):
# pick out the i-th column vector as the pivot
v = np.copy(X[:, i])
# Sweep over all previous Q-vectors and subtract off the projections
# This can be vectorized, but we'll do it in a loop for clarity
for j in range(i):
self.R[j, i] = np.dot(self.Q[:, j], X[:, i])
v -= self.R[j, i] * self.Q[:, j]
self.R[i, i] = np.linalg.norm(v)
self.Q[:, i] = v / self.R[i, i]
if self.store_history:
self.history.append([self.Q.copy(), self.R.copy()])
return self.Q, self.R
# Loop over column vectors
def qr(self, X):
self.Q = np.copy(X) # initial guess is just the original basis
self.R = np.zeros_like(X, dtype=float)
## Store the initial guess
if self.store_history:
self.history.append([self.Q.copy(), self.R.copy()])
for i in range(X.shape[1]):
# Calculate diagonal element of R before normalizing Q
self.R[i, i] = np.linalg.norm(self.Q[:, i])
# Normalize the i-th column of Q
self.Q[:, i] /= self.R[i, i]
# Loop to update remaining columns by removing the i-th column component
# along each of the previous columns
for j in range(i + 1, X.shape[1]):
self.R[i, j] = np.dot(self.Q[:, i], self.Q[:, j])
self.Q[:, j] -= self.R[i, j] * self.Q[:, i]
if self.store_history:
self.history.append([self.Q.copy(), self.R.copy()])
return self.Q, self.R
def solve(self, A, b):
"""
Solve Ax = b using QR factorization. We can see the
factorization as a form of preconditioning for the linear solver
"""
Q = self.qr(A)[0]
y = np.dot(Q.T, b)
return np.linalg.solve(self.R, y) # O(N^2) solve because R is upper triangular
def test_qr(self):
"""
Test the QR factorization solver
"""
a = np.random.randn(3, 3)
q, r = self.qr(a)
assert np.allclose(a, q @ r)
def test_solver(self):
A = np.random.randn(5, 5)
b = np.random.randn(5)
x = self.solve(A, b)
assert np.allclose(np.dot(A, x), b)
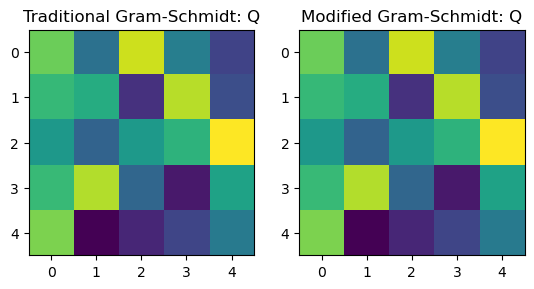
a = np.random.random((5, 5))
model = QRFactorizationSolver()
plt.figure()
plt.subplot(1, 2, 1)
plt.imshow(
model.qr0(a)[0]
)
plt.title('Traditional Gram-Schmidt: Q')
plt.subplot(1, 2, 2)
plt.imshow(
model.qr(a)[0]
)
plt.title('Modified Gram-Schmidt: Q')
plt.figure()
plt.figure()
plt.subplot(1, 2, 1)
plt.imshow(
model.qr0(a)[1]
)
plt.title('Traditional Gram-Schmidt: R')
plt.subplot(1, 2, 2)
plt.imshow(
model.qr(a)[1]
)
plt.title('Modified Gram-Schmidt: R')
print(np.allclose(model.qr0(a)[0], model.qr(a)[0]))True
<Figure size 640x480 with 0 Axes>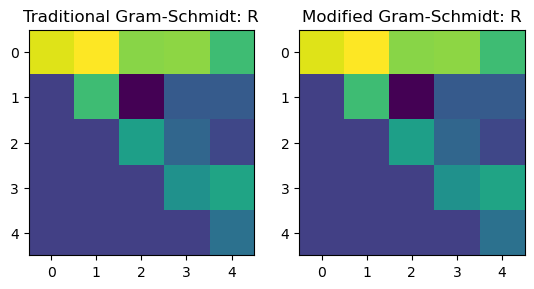
We can visualize the difference between Gram-Schmidt and Modified Gram-Schmidt by inspecting how the columnspace changes at each iteration of the algorithm
np.random.seed(0)
A = np.random.random((100, 100))
model_trad = QRFactorizationSolver(store_history=True)
q_trad, r_trad = model_trad.qr0(A.copy())
qr_trad_history = np.array(model_trad.history)
model_mod = QRFactorizationSolver(store_history=True)
q_mod, r_mod = model_mod.qr(A.copy())
qr_mod_history = np.array(model_mod.history)To understand the difference between the two algorithms, we can visualize how the column space of the matrix changes at each iteration. We visualize the column space of the matrix by looking at the first two elements in each column. In this space, we visualize 5 evenly-spaced vectors at column indices as the algorithm progresses iteratively.
## plot still frames
plt.figure(figsize=(10, 10))
for i in range(0, len(qr_trad_history)-1, 1):
plt.subplot(10, 10, i+1)
amat = qr_trad_history[i][0]
amat /= np.linalg.norm(amat, axis=0, keepdims=True)
plt.plot([0, amat[:, 0][0]], [0, amat[:, 0][1]])
plt.plot([0, amat[:, 10][0]], [0, amat[:, 10][1]])
plt.plot([0, amat[:, 20][0]], [0, amat[:, 20][1]])
plt.plot([0, amat[:, 50][0]], [0, amat[:, 50][1]])
plt.plot([0, amat[:, 99][0]], [0, amat[:, 99][1]])
plt.xlim([-0.15, 0.15])
plt.ylim([-0.15, 0.15])
plt.axis('off')
## plot still frames
plt.figure(figsize=(10, 10))
for i in range(0, len(qr_mod_history)-1, 1):
plt.subplot(10, 10, i+1)
amat = qr_mod_history[i][0]
amat /= np.linalg.norm(amat, axis=0, keepdims=True)
plt.plot([0, amat[:, 0][0]], [0, amat[:, 0][1]])
plt.plot([0, amat[:, 10][0]], [0, amat[:, 10][1]])
plt.plot([0, amat[:, 20][0]], [0, amat[:, 20][1]])
plt.plot([0, amat[:, 50][0]], [0, amat[:, 50][1]])
plt.plot([0, amat[:, 99][0]], [0, amat[:, 99][1]])
plt.xlim([-0.15, 0.15])
plt.ylim([-0.15, 0.15])
plt.axis('off')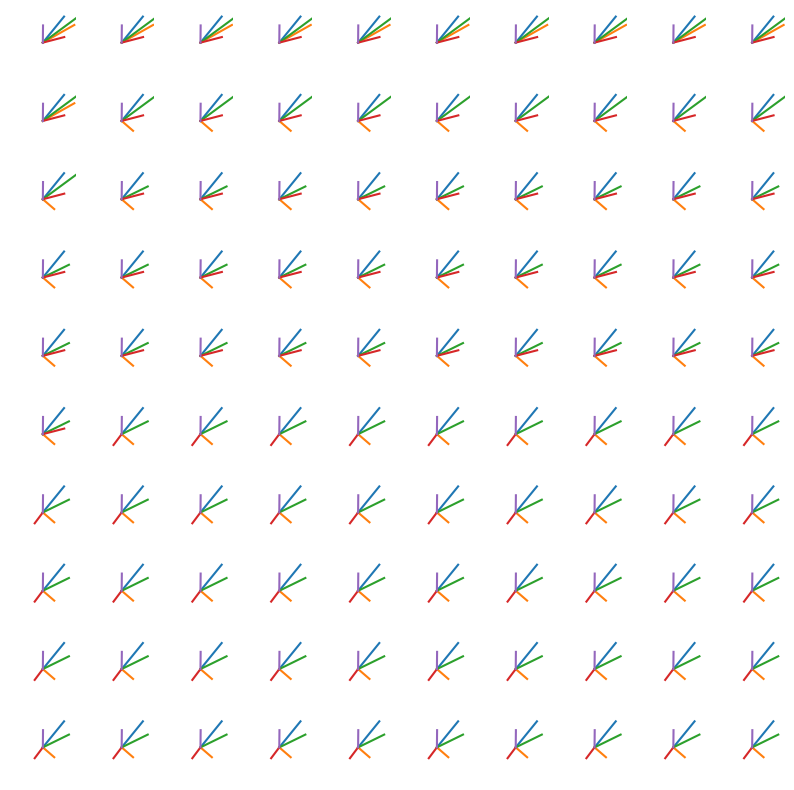

plt.figure(figsize=(7, 7))
plt.title('R matrix evolution during Traditional Gram-Schmidt')
for i, (q, r) in enumerate(qr_trad_history[::6][:16]):
plt.subplot(4, 4, i+1)
plt.imshow(np.log(1 + r), vmin=np.percentile(np.log(1 + r), 5), vmax=np.percentile(np.log(1 + r), 95))
plt.xticks([]); plt.yticks([])
plt.figure(figsize=(7, 7))
plt.title('R matrix evolution during Modified Gram-Schmidt')
for i, (q, r) in enumerate(qr_mod_history[::6][:16]):
plt.subplot(4, 4, i+1)
plt.imshow(np.log(1 + r), vmin=np.percentile(np.log(1 + r), 5), vmax=np.percentile(np.log(1 + r), 95))
plt.xticks([]); plt.yticks([])
## Make a video of the intermediate $R_k$ matrices
from matplotlib.animation import FuncAnimation
from IPython.display import HTML
all_r = np.log(1 + qr_trad_history[::10, 1])
fig, ax = plt.subplots()
im = ax.imshow(all_r[-1])
title = ax.set_title(f"R_0")
def update_frame(frame_idx):
im.set_data(all_r[frame_idx])
title.set_text(f"R_{frame_idx}")
return (im, title)
anim = FuncAnimation(fig, update_frame, frames=len(all_r[:50]), interval=200, blit=False)
html = HTML(anim.to_jshtml(default_mode="loop"))
plt.rcParams["animation.html"] = "jshtml" # use JS-based display (no ffmpeg needed)
plt.close(fig) # avoid a duplicate static figure
display(anim) # or: HTML(anim.to_jshtml(default_mode="loop"))
## Make a video of the intermediate $R_k$ matrices
from matplotlib.animation import FuncAnimation
from IPython.display import HTML
all_r = np.log(1 + qr_mod_history[::10, 1])
fig, ax = plt.subplots()
im = ax.imshow(all_r[-1])
title = ax.set_title(f"R_0")
def update_frame(frame_idx):
im.set_data(all_r[frame_idx])
title.set_text(f"R_{frame_idx}")
return (im, title)
anim = FuncAnimation(fig, update_frame, frames=len(all_r[:50]), interval=200, blit=False)
html = HTML(anim.to_jshtml(default_mode="loop"))
plt.rcParams["animation.html"] = "jshtml" # use JS-based display (no ffmpeg needed)
plt.close(fig) # avoid a duplicate static figure
display(anim) # or: HTML(anim.to_jshtml(default_mode="loop"))
We can now check the condition number of the matrix, and see how it affects the error of the QR decomposition. We create a matrix that is ill-conditioned by repeating a column vector and adding noise to it.
where , , and and is a small perturbation. We previously saw that the condition number scales as the inverse distance to the singular case, . For different values of , we compute the QR factorization and compute the error of the factorization as .
np.random.seed(0)
a = np.random.random(1000) # column vector dominant bearing direction
for epsilon in [1e-16, 1.0]:
print("Amplitude: ", epsilon)
## Build an ill-conditioned matrix by repeating the bearing vector a and adding noise
aa = np.tile(a, (len(a), 1)).T + np.random.random(size=(len(a), len(a))) * epsilon
print("Condition number: ", np.linalg.cond(aa))
model = QRFactorizationSolver()
q, r = model.qr0(aa)
# q, r = qr_factorization(aa)
print("Traditional QR Error: ", np.linalg.norm(q @ r - aa))
q, r = model.qr(aa)
# q, r = qr_factorization(aa)
print("Modified QR Error: ", np.linalg.norm(q @ r - aa))
print("\n")Amplitude: 1e-16
Condition number: inf
Traditional QR Error: 2.834117409350633e-06
/var/folders/79/zct6q7kx2yl6b1ryp2rsfbtc0000gr/T/ipykernel_79712/1865802443.py:63: RuntimeWarning: invalid value encountered in divide
self.Q[:, i] /= self.R[i, i]
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
Cell In[51], line 18
15 # q, r = qr_factorization(aa)
16 print("Traditional QR Error: ", np.linalg.norm(q @ r - aa))
---> 18 q, r = model.qr(aa)
19 # q, r = qr_factorization(aa)
20 print("Modified QR Error: ", np.linalg.norm(q @ r - aa))
Cell In[42], line 72, in QRFactorizationSolver.qr(self, X)
69 self.Q[:, j] -= self.R[i, j] * self.Q[:, i]
71 if self.store_history:
---> 72 self.history.append([self.Q.copy(), self.R.copy()])
74 return self.Q, self.R
KeyboardInterrupt: Because we stored all the intermediate values of the QR factorization, we can create a time series how the condition number of the intermediate matrices changes as we perform the QR algorithm using both Gram-Schmidt and Modified Gram-Schmidt. Recall that the condition number measures how close two rows or columns of a matrix are to being linearly dependent (parallel). For randomly-sampled matrices, we previously saw that the condition number scales linearly, .
However, for an orthogonal matrix, the condition number is 1, because the rows and columns are all orthogonal to each other. Thus, we can use the condition number of the intermediate matrices to monitor how the QR factorization interpolates between the ill-conditioned matrix and the well-conditioned orthogonal matrix .
all_cond_trad = list()
all_cond_mod = list()
for i in range(0, len(qr_trad_history)):
all_cond_trad.append(np.linalg.cond(qr_trad_history[i][0]))
all_cond_mod.append(np.linalg.cond(qr_mod_history[i][0]))
plt.plot(all_cond_trad, label='Traditional')
plt.plot(all_cond_mod, label='Modified')
plt.legend()
plt.title('Condition number of Q matrix during QR factorization')
plt.xlabel('Iteration')
plt.ylabel('Condition number')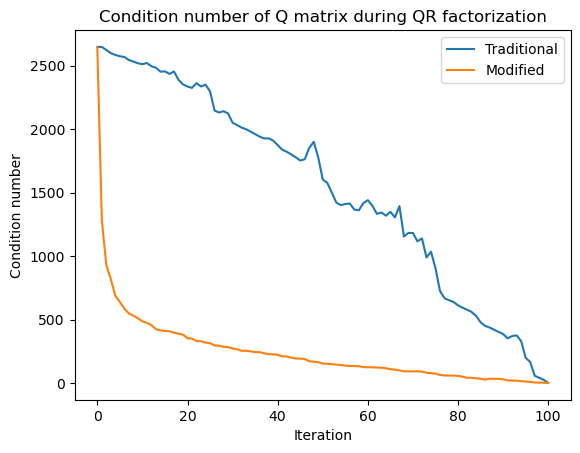
Community detection on the co-authorship network of physicists¶
We revisit our network consisting of coauthorship among physicists based arXiv postings in astro-ph. This graph contains nodes, which correspond to unique authors observed over the period 1993 -- 2003. If Author i and Author j coauthored a paper during that period, the nodes are connected. We can therefore summarize the graph using a sparse symmetric adjacency matrix
In order to analyze this large graph, we will downsample it to a smaller graph with nodes representing the most highly-connected authors. This dataset is from the Stanford SNAP database
import io
import gzip
import urllib.request
import networkx as nx
# subject = "CondMat"
# subject = "HepPh"
# subject = "HepTh"
# subject = "GrQc"
subject = "AstroPh"
url = f"https://snap.stanford.edu/data/ca-{subject}.txt.gz"
with urllib.request.urlopen(url) as resp:
with gzip.open(io.BytesIO(resp.read()), mode="rt") as fh:
g = nx.read_edgelist(fh, comments="#", nodetype=int)
## Load the full coauthorship network
# fpath = "../resources/ca-AstroPh.txt.gz"
# fpath = "../resources/ca-CondMat.txt.gz"
# g = nx.read_edgelist(fpath)
## Create a subgraph of the 1000 most connected authors
subgraph = sorted(g.degree, key=lambda x: x[1], reverse=True)[:4000]
subgraph = [x[0] for x in subgraph]
g2 = g.subgraph(subgraph)
# rename nodes to sequential integers as they would appear in an adjacency matrix
g2 = nx.convert_node_labels_to_integers(g2, first_label=0)
pos = nx.spring_layout(g2)
# pos = nx.kamada_kawai_layout(g2)
# nx.draw_spring(g2, pos=pos, node_size=10, node_color='black', edge_color='gray', width=0.5)
nx.draw(g2, pos=pos, node_size=5, node_color='black', edge_color='gray', width=0.5, alpha=0.5)
plt.show()
Random walks on graphs: The ensemble limit¶
Recall that random walks on the co-authorship network exhibit a non-uniform invariant distribution, where the probability of visiting a node is proportional to its degree. We can exploit this property to probe global properties (the invariant distribution) of the network using local probes (random walks).
We can interpret the adjacency matrix as a transition matrix for a Markov chain, which governs the dynamics of an ensemble of random walkers on the graph. The probability of a walker transitioning from node to node in one step is given by the transition matrix , where the denominator is the degree of node . Notice that even if is symmetric, is not symmetric, because the transition probability depends on the out-degree of the node.
What is the long-term behavior of this Markov chain? We can find the invariant distribution by solving the equation , which is equivalent to finding the eigenvector of with eigenvalue 1. Our definition of the Markov chain implies that we are treating the adjacency matrix as defining a Markov chain in discrete time
Spectral graph analysis¶
We know that the eigenvector of with eigenvalue 1 is the invariant distribution of the Markov chain. What do the other eigenvectors tell us about our graph? Physically, Markov chain describes the dynamics of an ensemble of random walkers on the graph. While the invariant distribution describes the infinite-horizon behavior of the ensemble, the other eigenvectors describe the transient behavior of this distribution. In a physical system, this corresponds to regions of the graph that have low connectivity among them, causing walkers to get trapped for extended (but not infinite) durations. For a random graph, these trapping regions can be used for community detection.
We saw before that there is a clump of highly-collaborative authors in our coauthorship network, but there also appear to be several nearly-isolated subcommunities. We can quantify this observation and these clumps using spectral analysis of the graph, We define the adjacency matrix of the graph as a matrix where if nodes and are connected, and otherwise. We define a Markov transition matrix from this adjacency matrix as
where the denominator is the total number of connections for node . This matrix is row-stochastic, meaning that the sum of each row is 1. This matrix represents a random walk on the graph, where at each step, we randomly select a neighbor of the current node, and then move to that node. The probability of moving to a given node is proportional to the number of connections that node has to the current node.
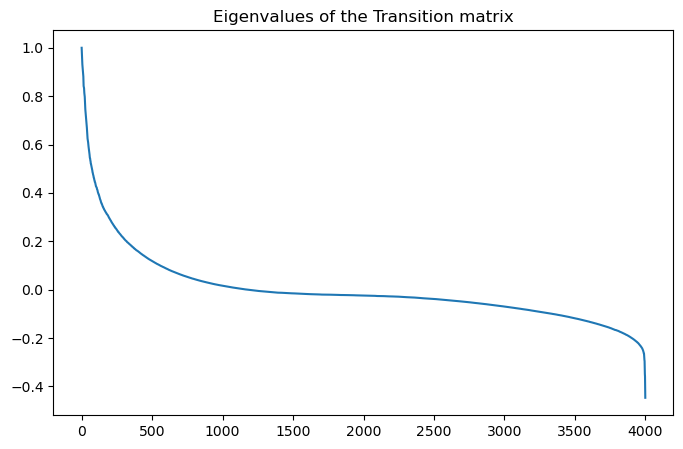
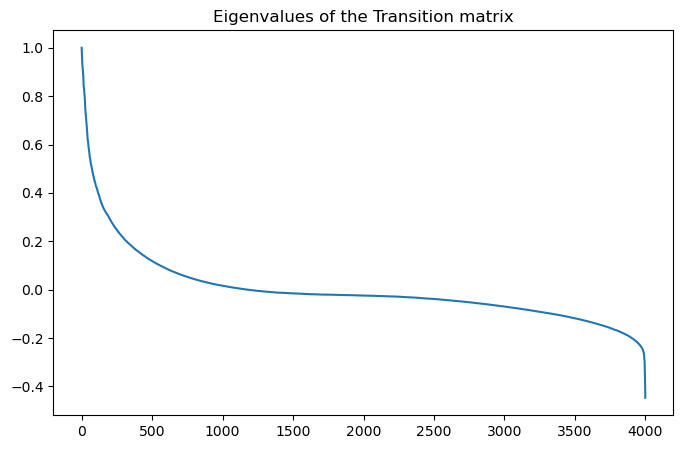
print(np.sort(eigenvalues)[::-1][:5])[1. +0.j 0.98398384+0.j 0.96511985+0.j 0.94907775+0.j
0.93820795+0.j]
# use spectral graph partitioning
## Create the adjacency matrix
A = nx.adjacency_matrix(g2).todense()
A = np.array(A)
# convert to discrete-time Markov transition matrix
T = A / np.sum(A, axis=0, keepdims=True)
## Create the degree matrix
# D = np.diag(np.sum(A, axis=0))
# D = np.identity(A.shape[0]) # unweighted graph
## Create the graph Laplacian matrix
# L = D - A
## Compute the eigenvalues and eigenvectors
eigenvalues, eigenvectors = np.linalg.eig(T)
## Sort the eigenvalues and eigenvectors
sort_inds = np.argsort(eigenvalues)[::-1]
eigenvalues, eigenvectors = eigenvalues[sort_inds], eigenvectors[:, sort_inds]
## Plot the eigenvalues in descending order
plt.figure(figsize=(8, 5))
plt.plot(eigenvalues)
plt.title("Eigenvalues of the Transition matrix")
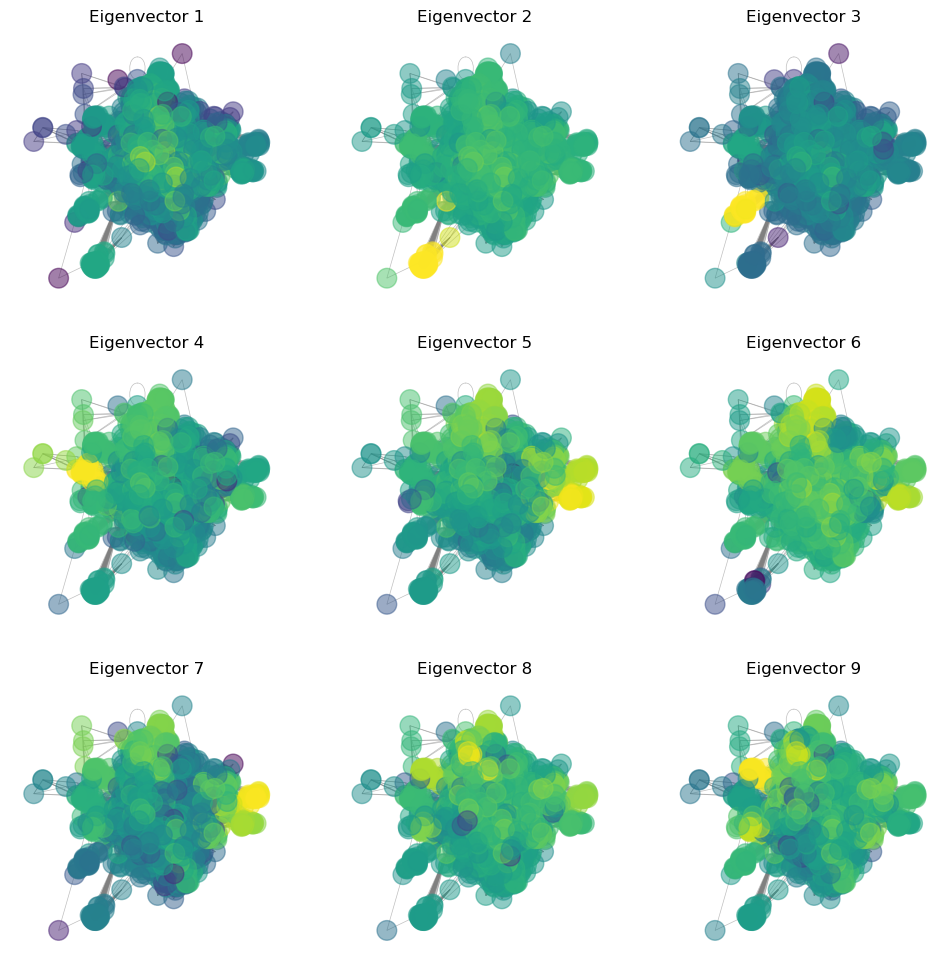
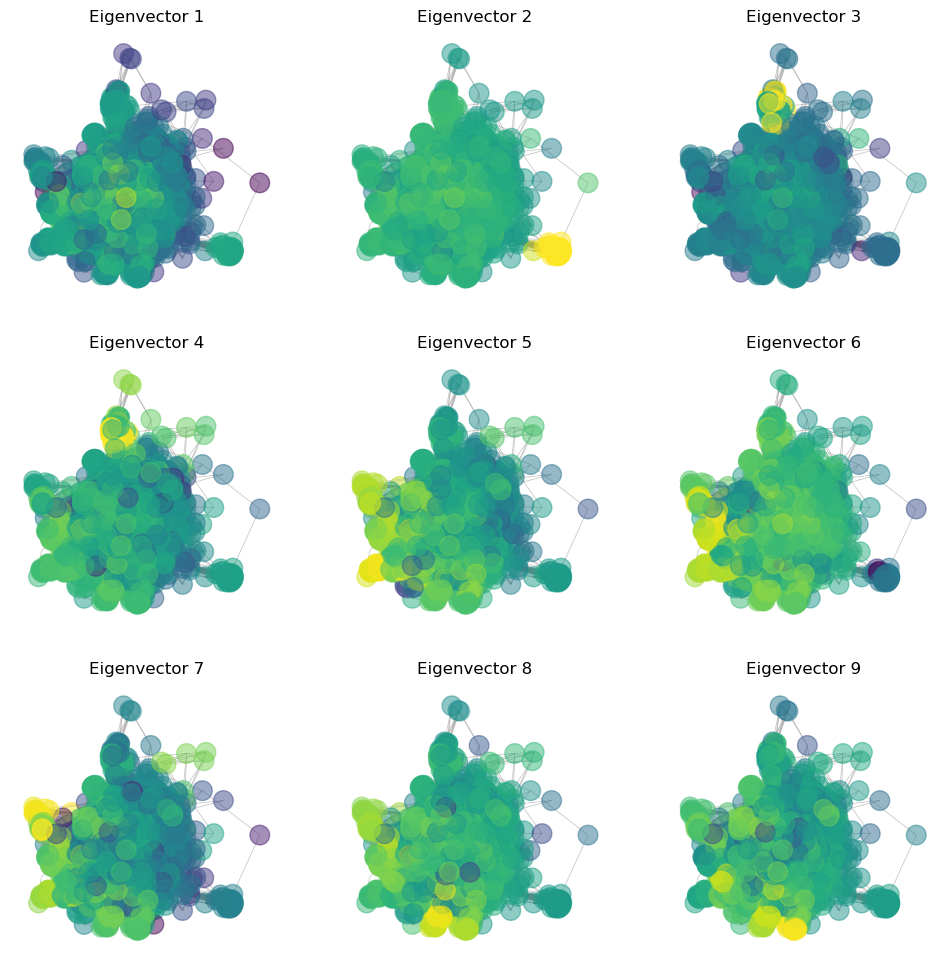
## Plot the leading eigenvectors as colors on the graph
plt.figure(figsize=(12, 12))
for i in range(9):
plt.subplot(3, 3, i+1)
nx.draw(g2, pos=pos, node_size=200, node_color=np.log(np.abs(eigenvectors[:, i])), edge_color='gray', width=0.5, alpha=0.5)
plt.title("Eigenvector {}".format(i+1))/Users/william/mamba/envs/cphy/lib/python3.13/site-packages/matplotlib/cbook.py:1719: ComplexWarning: Casting complex values to real discards the imaginary part
return math.isfinite(val)
/Users/william/mamba/envs/cphy/lib/python3.13/site-packages/matplotlib/cbook.py:1355: ComplexWarning: Casting complex values to real discards the imaginary part
return np.asarray(x, float)
# use spectral graph partitioning
## Create the adjacency matrix
A = nx.adjacency_matrix(g2).todense()
A = np.array(A)
# convert to discrete-time Markov transition matrix
T = A / np.sum(A, axis=0, keepdims=True)
## Create the degree matrix
# D = np.diag(np.sum(A, axis=0))
# D = np.identity(A.shape[0]) # unweighted graph
## Create the graph Laplacian matrix
# L = D - A
## Compute the eigenvalues and eigenvectors
eigenvalues, eigenvectors = np.linalg.eig(T)
## Sort the eigenvalues and eigenvectors
sort_inds = np.argsort(eigenvalues)[::-1]
eigenvalues, eigenvectors = eigenvalues[sort_inds], eigenvectors[:, sort_inds]
## Plot the eigenvalues in descending order
plt.figure(figsize=(8, 5))
plt.plot(eigenvalues)
plt.title("Eigenvalues of the Transition matrix")
## Plot the leading eigenvectors as colors on the graph
plt.figure(figsize=(12, 12))
for i in range(9):
plt.subplot(3, 3, i+1)
nx.draw(g2, pos=pos, node_size=200, node_color=np.log(np.abs(eigenvectors[:, i])), edge_color='gray', width=0.5, alpha=0.5)
plt.title("Eigenvector {}".format(i+1))
/Users/william/mamba/envs/cphy/lib/python3.13/site-packages/matplotlib/cbook.py:1719: ComplexWarning: Casting complex values to real discards the imaginary part
return math.isfinite(val)
/Users/william/mamba/envs/cphy/lib/python3.13/site-packages/matplotlib/cbook.py:1355: ComplexWarning: Casting complex values to real discards the imaginary part
return np.asarray(x, float)
# use spectral graph partitioning
## Create the adjacency matrix
A = nx.adjacency_matrix(g2).todense()
A = np.array(A)
# convert to discrete-time Markov transition matrix
T = A / np.sum(A, axis=0, keepdims=True)
## Create the degree matrix
# D = np.diag(np.sum(A, axis=0))
# D = np.identity(A.shape[0]) # unweighted graph
## Create the graph Laplacian matrix
# L = D - A
## Compute the eigenvalues and eigenvectors
eigenvalues, eigenvectors = np.linalg.eig(T)
## Sort the eigenvalues and eigenvectors
sort_inds = np.argsort(eigenvalues)[::-1]
eigenvalues, eigenvectors = eigenvalues[sort_inds], eigenvectors[:, sort_inds]
## Plot the eigenvalues in descending order
plt.figure(figsize=(8, 5))
plt.plot(eigenvalues)
plt.title("Eigenvalues of the Transition matrix")
## Plot the leading eigenvectors as colors on the graph
plt.figure(figsize=(12, 12))
for i in range(9):
plt.subplot(3, 3, i+1)
nx.draw(g2, pos=pos, node_size=200, node_color=np.log(np.abs(eigenvectors[:, i])), edge_color='gray', width=0.5, alpha=0.5)
plt.title("Eigenvector {}".format(i+1))
/Users/william/micromamba/envs/cphy/lib/python3.11/site-packages/matplotlib/cbook.py:1699: ComplexWarning: Casting complex values to real discards the imaginary part
return math.isfinite(val)
/Users/william/micromamba/envs/cphy/lib/python3.11/site-packages/matplotlib/cbook.py:1345: ComplexWarning: Casting complex values to real discards the imaginary part
return np.asarray(x, float)
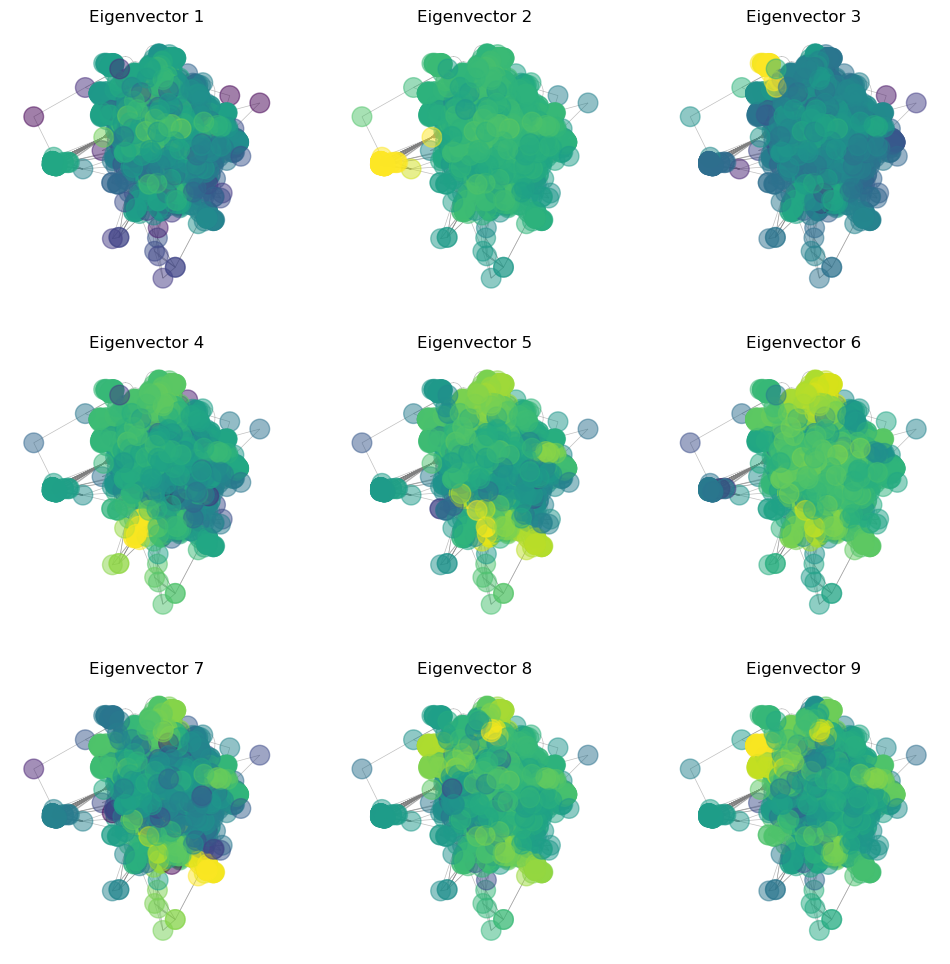
What do the different eigenvectors mean?¶
Leading Eigenvalues¶
A discrete-time Markov chain has leading eigenvector associated with the eigenvalue 1. This eigenvector represents the invariant distribution of the Markov chain, and is the long-term probability of finding the random walker at a given node. However, if there are multiple fully-connected subgraphs, there will be degeneracy with multiple eigenvectors associated with the eigenvalue 1. In the non-degenerate case, the leading eigenvector is unique. The second eigenvector of the transition matrix is associated with the second-largest eigenvalue. This represents the longest-lived transients in the Markov chain dynamics
Negative Eigenvalue¶
If there are negative eigenvalues, these indicate cycles in the graph. The eigenvectors associated with these eigenvalues represent the oscillatory behavior of the random walker as it cycles through the graph. For example, consider the transition matrix:
A random walker will oscillate between the two nodes. The invariant density associated with the leading eigenvalue is given by
Because, on average, the walker spends half of its time at each node. The eigenvector associated with the second eigenvalue is given by
Because the walker spends one step at the first node, and then one step at the second node, and then repeats this cycle.
Laplacian eigenmaps¶
We saw that we can associate a discrete-time Markov chain with the adjacency matrix of a graph. We can also associate a continuous-time Markov chain with the adjacency matrix of a graph. In this case, the generator matrix is defined as
This defines a continuous-time Markov chain, with differential equation
where is the probability distribution of the random walker at time . The solution to this differential equation is given by
where is the matrix exponential.
The generator matrix is related to the transition matrix by the relation , where is the identity matrix. This means that the eigenvalues of are related to the eigenvalues of by . This means that the leading eigenvalue of is 0, and the leading eigenvector of is the same as the leading eigenvector of .
The Graph Laplacian¶
The graph Laplacian is defined as
where is a diagonal matrix, where is the degree of node . The graph Laplacian is a symmetric matrix, and so it has a complete set of orthonormal eigenvectors. The eigenvectors of the graph Laplacian are related to the eigenvectors of the transition matrix by
where is the degree of node .
import numpy as np
from scipy.sparse import csr_matrix
from scipy.sparse.csgraph import shortest_path
def amat_to_dist(A, *, directed=True, unweighted=True,
unreachable_value=1e10, out_dtype=np.float32):
"""
Args:
A (array_like or sparse): N×N adjacency/weight matrix.
directed (bool): Treat graph as directed.
unweighted (bool): If True, any nonzero entry is an edge of weight 1.
unreachable_value (float): Value to use when no path exists.
out_dtype (np.dtype): dtype of the returned distance matrix.
Returns:
np.ndarray: N×N matrix of shortest-path distances.
"""
A_csr = csr_matrix(A)
D = shortest_path(A_csr, directed=directed, unweighted=unweighted)
D = D.astype(out_dtype, copy=False)
if np.isinf(D).any():
D[np.isinf(D)] = out_dtype.type(unreachable_value) if hasattr(out_dtype, "type") else unreachable_value
return Dimport networkx as nx
from scipy.sparse.linalg import eigs
from scipy.sparse import csr_matrix
from scipy.sparse.csgraph import shortest_path
class LaplacianEigenmap:
"""
A class for computing the Laplacian Eigenmap of a graph
Attributes:
n_components (int): The number of components to return.
"""
def __init__(self, n_components=2):
self.n_components = n_components
def amat_to_dist(self, A, directed=False, unweighted=True, unreachable_value=1e10, out_dtype=np.float32):
"""convert adjacency matrix to distance matrix with shortest path"""
A_csr = csr_matrix(A)
D = shortest_path(A_csr, directed=directed, unweighted=unweighted)
D = D.astype(out_dtype, copy=False)
if np.isinf(D).any():
D[np.isinf(D)] = out_dtype.type(unreachable_value) if hasattr(out_dtype, "type") else unreachable_value
return D
def fit_transform(self, A):
# A is the adjacency matrix
# Convert adjacency matrix to distance matrix
A = self.amat_to_dist(A)
# Compute degree matrix
D = np.diag(np.sum(A, axis=1)).astype(float)
# Compute Laplacian matrix
L = (D - A).astype(float)
# Eigendecomposition
vals, vecs = eigs(csr_matrix(L, dtype='float64'), k=self.n_components + 1,
M=csr_matrix(D, dtype='float64'), which='SM')
# Sort eigenpairs and get relevant eigenvectors
sorted_indices = np.argsort(vals.real)
relevant_indices = sorted_indices[1:self.n_components + 1] # Exclude smallest eigenvalue
# Projected data
Y = vecs[:, relevant_indices].real
return Y
model = LaplacianEigenmap(n_components=2)
A = nx.adjacency_matrix(g2).todense()
A = np.array(A)
degrees = np.sum(A, axis=1)
sort_inds = np.argsort(degrees)[::-1]
A = A[sort_inds][:, sort_inds]
Y = model.fit_transform(A)
plt.figure(figsize=(8, 8))
plt.scatter(Y[:, 0], Y[:, 1], s=4, c=np.log(degrees[sort_inds]))
plt.title("Laplacian Eigenmap")
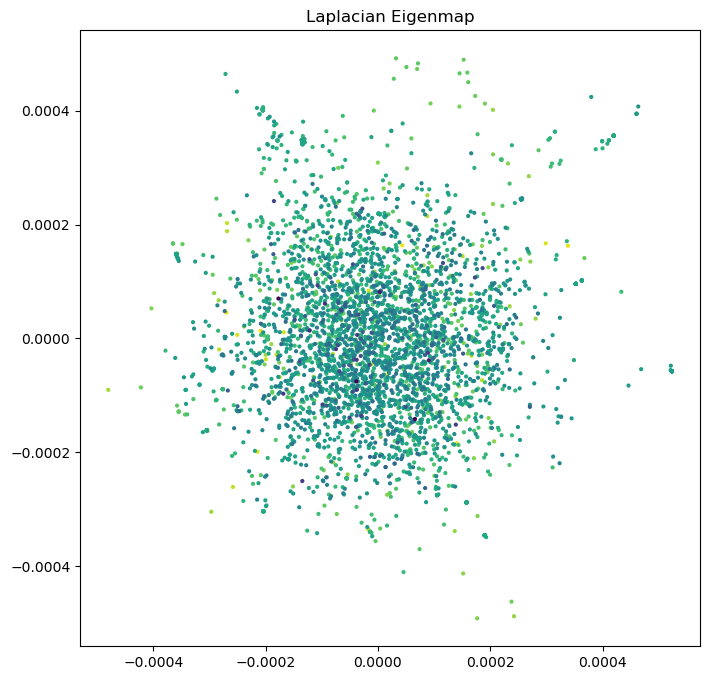
nx.draw(g2, pos=Y, node_size=10, edge_color='gray', width=0.1)
pos2 = nx.spectral_layout(g2)
nx.draw(g2, pos=pos2, node_size=10, edge_color='gray', width=0.1)
nx.draw(g2, pos=pos, node_size=10, edge_color='gray', width=0.1)
plt.figure(figsize=(8, 8))
plt.scatter(Y[:, 0], Y[:, 1], s=200, c=np.log(degrees[sort_inds]))
plt.title("Laplacian Eigenmap")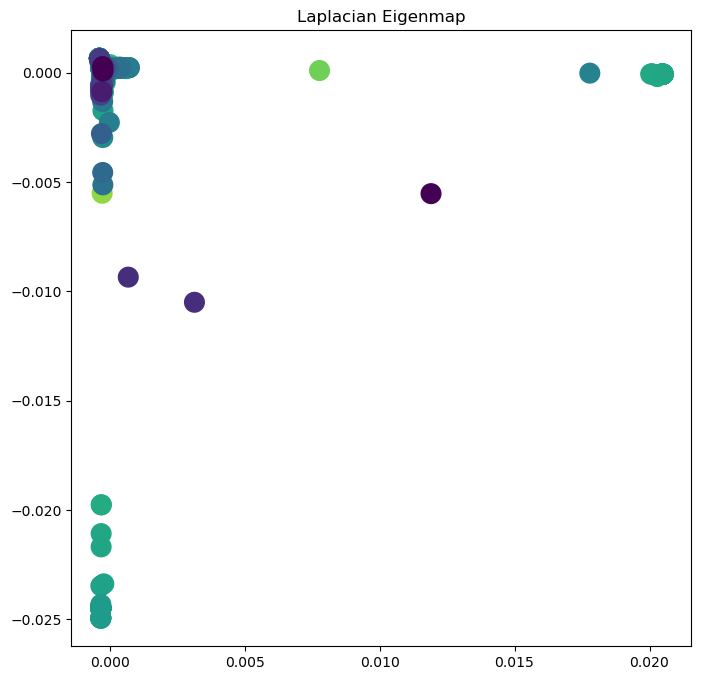
# pos = nx.spring_layout(g2)
# pos = nx.kamada_kawai_layout(g2)
# nx.draw_spring(g2, pos=pos, node_size=10, node_color='black', edge_color='gray', width=0.5)
nx.draw(g2, pos=Y, node_size=5, node_color='black', edge_color='gray', width=0.5, alpha=0.5)
plt.show()
How do we interpret the eigenspectrum of a graph?¶
The eigenvectors of the adjacency matrix of a graph represent the “modes” of the graph. The adjacency matrix can be used to define a Markov process on the graph, which evolves a probability distribution of random walkers over the nodes of the graph. The leading eigenvector of the adjacency matrix represents the stationary distributions of this Markov process, while the subsequent eigenvectors represent long-lived transients. The first eigenvector thus gives the long-term probability distribution of which nodes random walkers will be found on, and so it can be used as a loose ranking of the importance of nodes in the graph