A note on cloud-hosted notebooks. If you are running a notebook on a cloud provider, such as Google Colab or CodeOcean, remember to save your work frequently. Cloud notebooks will occasionally restart after a fixed duration, crash, or prolonged inactivity, requiring you to re-run code.

import numpy as np
import matplotlib.pyplot as plt
%matplotlib inlineFinding eigenspectra is difficult for large matrices¶
Suppose we are given a square matrix . How can we find the eigenvalues and eigenvectors of this matrix numerically? The schoolyard method for performing this calculation consists of first solving the characteristic equation for the eigenvalues such that
In principle, this equation always factors into a polynomial with solutions corresponding to the eigenvalues . However, as grows larger, it becomes progressively more difficult to factor the equation and find the roots , since the polynomial has order . At large , it often becomes impractical to use numerical root-finding to solve the eigenvalue problem using schoolyard methods.
The power method¶
The power method is a purely iterative method for finding the leading eigenvector of large matrices. The basic algorithm is as follows:
We start with a matrix .
Pick a random vector , and convert it to a unit vector by scaling it with its own norm .
Compute the matrix product of our matrix with the random unit vector, and then update the vector .
Re-normalize the resulting vector, producing a new unit vector,
Repeat steps 2 and 3 until the elements of the output unit vector fluctuate less than a pre-specified tolerance
Multiply the resulting vector by the original matrix . The length of the resulting vector gives the magnitude of the leading eigenvalue
The power method derivation¶
Suppose we seek to find the leading eigenvector of a matrix . If the matrix is non-singular, then it has a full-rank eigenbasis , spanned by the independent, orthonormal eigenvectors such that . We start with a our random vector , and write it in terms of the basis ,
We next compute the norm of the output vector
for simplicity, we define . Rescaling our transformed vector by the norm, we apply the matrix again,
This quantity has the norm,
Now we consider the limit as as . Without loss of generality, we assume that the eigenvalues of are ordered by their magnitude, . The series above diverges geometrically as we iterate repeatedly, such that
To Do¶
Please complete the following tasks and answer the included questions. You can edit a Markdown cell in Jupyter by double-clicking on it. To return the cell to its formatted form, press [Shift]+[Enter].
Implement the power method in Python. The starter code below outlines the basic structure of the algorithm. Try running the code with different random seeds, and see if you can find matrices where the power method fails to converge.
Your Answer: Complete the code belowSometimes you’ll notice that the power method fails to converge to the correct solution. What is special about randomly-sampled matrices where this occurs? How does the direction of the starting vector affect the time it takes to reach a solution?
Your Answer: Suppose that we interpret a given linear matrix as describing a discrete-time linear dynamical system, . What kind of dynamics does the power method exhibit? What about the pathological cases you discussed in the previous solution?
Your Answer:The power method represents a basic optimization problem, where we are searching for a convergent solution. We saw that our method occasionally fails to find the correct solution. One way to improve our optimization would be to add a momentum term of the form
where . How would you modify your implementation of the power method, in order to allow momentum? What kinds of pathological dynamics would the momentum term help us avoid? You can answer this question empirically or theoretically.
Your Answer:Similar to the momentum term, there is also a way to add additional damping to the update rule. What kinds of dynamics would that help us avoid? You can answer this question empirically or theoretically.
Your Answer: import warnings
class SpectralDecompositionPowerMethod:
"""
Store the output vector in the object attribute self.components_ and the
associated eigenvalue in the object attribute self.singular_values_
Why this code structure and attribute names? We are using the convention used by
the popular scikit-learn machine learning library:
https://scikit-learn.org/stable/modules/generated/sklearn.decomposition.PCA.html
Parameters
max_iter (int): maximum number of iterations to for the calculation
tolerance (float): fractional change in solution to stop iteration early
gamma (float): momentum parameter for the power method
random_state (int): random seed for reproducibility
store_intermediate_results (bool): whether to store the intermediate results as
the power method iterates
stored_eigenvalues (list): If store_intermediate_results is active, a list of
eigenvalues at each iteration
stored_eigenvectors (list): If store_intermediate_results is active, a list of
eigenvectors at each iteration
"""
def __init__(self,
max_iter=1000,
tolerance=1e-5,
gamma=0.0,
random_state=None,
store_intermediate_results=False
):
########## YOUR CODE HERE ##########
#
# YOUR CODE HERE
#
########## YOUR CODE HERE ##########
raise NotImplementedError()
def fit(self, A):
"""
Perform the power method with random initialization, and optionally store
intermediate estimates of the eigenvalue and eigenvectors at each iteration.
You can add an early stopping criterion based on the tolerance parameter.
"""
########## YOUR CODE HERE ##########
#
# YOUR CODE HERE
# Hint: keep track of your normalization factors, and watch out for passing
# arrays by value vs. by reference. This method should return self
#
########## YOUR CODE HERE ##########
raise NotImplementedError()
Test and use your code¶
If you are working from a local fork of the entire course, then you already have access to the solutions. In this case, make sure to
git pullto make sure that you are up-to-date (save your work first).If you are working from a single downloaded notebook, or are working in Google Colab, then you will need to manually download the solutions file from the course repository. The lines below will do this for you.
## Optional: Download and import the instructor solutions
import requests
ns={}
exec(requests.get('https://raw.githubusercontent.com/williamgilpin/cphy/main/hw/solutions/eigen.py', timeout=10).text, ns);
SpectralDecompositionPowerMethod = ns['SpectralDecompositionPowerMethod']## Use the default eigensystem calculator in numpy as a point of comparison
def eigmax_numpy(A):
"""
Compute the maximum eigenvalue and associated eigenvector in a matrix with Numpy.
"""
eigsys = np.linalg.eig(A)
ind = np.abs(eigsys[0]).argmax()
return np.real(eigsys[0][ind]), np.real(eigsys[1][:, ind])
np.random.seed(2) # for reproducibility
mm = np.random.random(size=(10, 10)) / 100
mm = np.random.normal(size=(10, 10))# / 100 # these matrices fail to converge more often
# mm += mm.T # force hermitian
print(np.linalg.cond(mm.T))
model = SpectralDecompositionPowerMethod(store_intermediate_results=True, gamma=0.0)
model.fit(mm);
print(f"Power method solution: {model.singular_values_}")
print(f"Numpy solution: {eigmax_numpy(mm)[0]}")
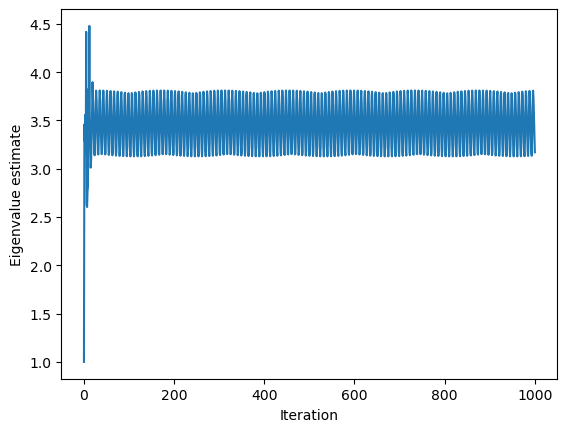
plt.figure()
plt.plot(model.stored_eigenvalues)
plt.xlabel("Iteration")
plt.ylabel("Eigenvalue estimate")
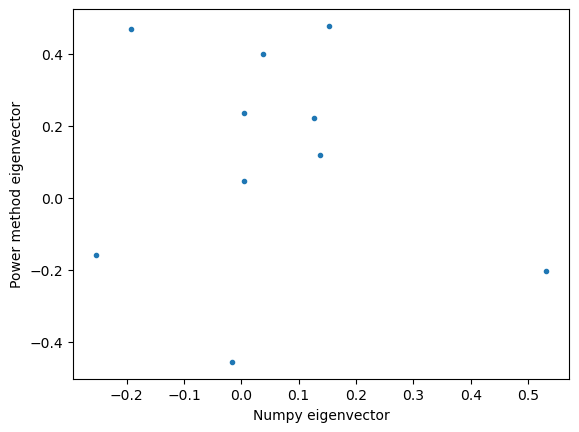
plt.figure()
plt.plot(eigmax_numpy(mm)[1], model.components_, '.')
plt.xlabel("Numpy eigenvector")
plt.ylabel("Power method eigenvector")18.49845783535237
Running with Instructor Solutions. If you meant to run your own code, do not import from solutions
Power method solution: 3.170316298624699
Numpy solution: -3.186026702152251
Follow-up ideas and additional information¶
The runtime complexity of root-finding for a polynomial of the order, is poorly-defined as a function of , because there are no guaranteed methods for high-order polynomials other than iterative root-finding. A good guess would be runtime with a large prefactor (for each of roots, perform a line search, discover a solution, and then reduce the polynomial in degree). However, because finding the initial polynomial via taking a determinant has runtime , the overall runtime of this method is still unfavorable compared to iterative methods.
The power method gives us the leading eigenvalue and eigenvector of a matrix. What about the full eigenspectrum of the matrix? A more sophisticated version of the power method is the so-called QR algorithm. Recall how, at each step, we renormalized our eigenvector estimate. If we instead propagate a bundle of random vectors (in order to estimate all of the different eigenvectors), the equivalent of renormalization would be repeated orthonormalization via a mechanism such as Gram-Schmidt. The QR algorithm basically performs this iterative re-orthonormalization very quickly via the QR factorization of the bundle.
We just described an iterative algorithm for finding eigenvalues, and we discussed one improvement via the addition of momentum term. It turns out there’s lots of other ways to improve our update rule, such as by adjusting the eigenvector estimate at a rate proportional to the previous change (a gradient). Because gradient descent is used to train modern neural networks, there is a lot of research describing the convergence properties of various update rules; here’s a nice list of some common methods. If you want to further improve your power method implementation, try using some of these more modern rules instead.
We made an analogy between the iterative power method and the action of a linear dynamical system. For nonlinear dynamical systems, an algorithm very similar to the power method is used to calculate the Lyapunov exponents, which quantify the degree of chaos present in the system. On some level, we can think of nonlinear dynamical systems as linear dynamical systems where the elements of the matrix change with time and position.
Often in scientific computing we encounter highly-rectangular matrices, , . For these systems the eigenvectors are not defined, and the schoolyard polynomial equation for the eigenvalues will be overdetermined () or underdetermined (). However, we can instead calculate the eigenspectrum of the “squared” matrices or , where the dagger indicates the conjugate transpose. We refer to the eigenvectors as the “right” or “left” singular vectors, respectively, and their associated eigenvalues are called the singular values. All non-square matrices admit a singular value decomposition of the form
where the columns of are the right singular vectors, the columns of are the left singular vectors, and is a square diagonal matrix with the eigenvalues of along the diagonal. Since the eigenvalues and eigenvectors can be listed in any order, by convention we normally list the elements in descending order of eigenvalue magnitude.
2. Principal Component Analysis and Unsupervised Learning¶
When working with high-dimensional data, it can be helpful to reduce the effective dimensionality of the data by reducing the number of features. For example, suppose we are synthesizing a crystalline material via epitaxy. After preparing a sample, we can measure several properties: reflectivity, conductance, brittleness, etc. After creating a bunch of samples, and measuring several properties for each sample, we want to analyze the relationship among the different features/properties in a systematic way.
If we denote a given experiment with the measurement vector , then we can represent all of our experiments in a design matrix , where denotes the number of samples or experiments, and represents the number of measurements or features we record for each sample.
We know that several of our features are highly correlated across our experiments. Can we find a lower-dimensional representation of our dataset , , that describes the majority of variation in our dataset?
In principle, reducing the dimensionality of a dataset requires finding an injective function that maps each set of measured features to some lower dimensional set of features,
If this function is linear in the features, , then this problem reduces to finding the coefficient matrix . For this linear case, we can use Principal Component Analysis (PCA).
The basic idea of PCA is that the eigenvectors of a dataset’s covariance matrix reveal dominant patterns within the dataset, and so by projecting the dataset onto a subset of these eigenvectors, we can find lower-dimensional representation of the data. PCA is optimal in the sense that the first principal components represent a unique dimensional representation of a dataset that captures the most variance in the original data. Because PCA is a linear transform (we project the data on a set of basis vectors), then if we project the original dataset onto the full set of eigenvectors, we basically will have rotated our dataset in a high-dimensional vector space, without discarding any information. More info about PCA here
Mathematically, the steps of computing PCA are relatively simple. We center our data by the feature-wise mean vector, compute the covariance matrix, compute the eigenvectors, sort them in descending order of accompanying eigenvalue magnitude, and then stack the first eigenvectors to create the coefficient matrix
where denotes the eigenvector of . The coefficient matrix denotes the first eigenvectors stacked on top of each other, sorted in decreasing order of the magnitude of their associated eigenvalue. In this context, we call the eigenvalues the “singular values” of the original data matrix , while the eigenvectors are the principal components. The central idea of PCA is that the first principal components (sorted in descending order of eigenvalue magnitude) represent the optimal variance-preserving dimensional approximation of the original dataset.
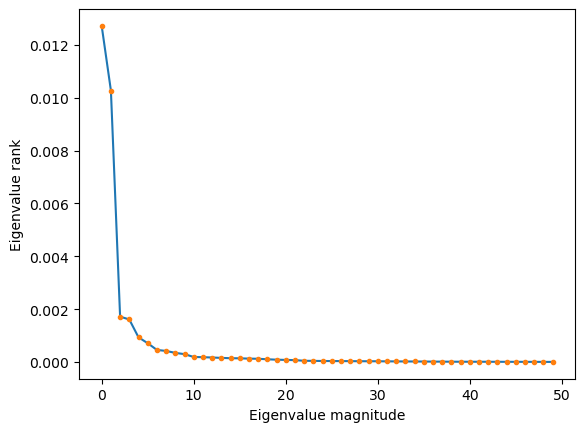
Our choice of will depend on the properties of the dataset. In practice, we usually plot all of the eigenvalues in descending order of magnitude, and then look for a steep dropoff in their average magnitude---this indicates low dimensionality in the underlying dataset. Deciding the value of determines whether we favor a more concise and compressed representation, or a more accurate one; and various heuristics exist for determining the right threshold. After choosing , we discard the remaining eigenvectors.
What’s nice about PCA is that it generalizes well even to cases where . For example, if we are working with high-resolution images, each pixel is essentially a separate feature, and so .
PCA falls broadly under the category of unsupervised learning, which are machine learning techniques that seek to discover structure and patterns in complex data, without external information like annotations that guide the learning process. Instead, unsupervised learning techniques find alternative representations of datasets that satisfy certain desiderata. In the case of PCA, we find a representation of the data in which the first few discovered variables capture the majority of the dataset’s variance, thus compressing meaningful properties of the dataset into a lower-dimensional representation.
The von Karman vortex street¶
As an example dataset, we are going to use the velocity field created as a fluid flow passes over a cylinder. At low flow speeds or high fluid viscosities, the flow parts around the cylinder and then smoothly rejoins behind it. However, as the speed or viscosity decreases, an instability appears in which the flow begins to oscillate behind the cylinder, giving rise to sets of counter-rotating vortices that break off the cylinder and pass into the wake. As speed further increases, this sequence of vortices becomes more chaotic, leading to irregular downstream structure.
The control parameter governing this transition from ordered to chaotic flow is the Reynolds number,
where is the fluid density, is the fluid speed, is the characteristic length of the cylinder, and is the fluid viscosity. Because and are both material properties of the fluid, they are often combined into a single parameter, the kinematic viscosity . For water, the kinematic viscosity under standard conditions is , and for air, . The Reynolds number is a dimensionless quantity that measures the relative importance of inertial forces to viscous forces in the system. In general, flows become more turbulent at higher Reynolds numbers, and they become more frictional at lower Reynolds numbers. For example, the flow through a jet engine can reach , while pouring maple syrup has .
In the class repository, we have included very large datasets corresponding to time series of snapshots showing the velocity field of the flow past a cylinder. We include separate datasets from several different Reynolds numbers, which show how the structure of the von Karman instability changes as the flow becomes more turbulent.
To Do¶
Please complete the following tasks and answer the included questions. You can edit a Markdown cell in Jupyter by double-clicking on it. To return the cell to its formatted form, press [Shift]+[Enter].
Download the von Karman dataset and explore it using the code below. What symmetries are present in the data? Do any symmetries change as we increase the Reynolds number? Note: If you are working from a fork of the course repository, the dataset should load automatically. Otherwise, the cells below should automatically download the data sets and place them in higher-level directory
../resources. If the automatic download fails, you may need to manually download the von Karman dataset and place it in the correct directory.
Your Answer: Run the code belowImplement Principal Component Analysis in Python. I have included my outline code below; we are going to use multiple inheritance in order to make our implementation compatible with standard conventions for machine learning in Python. I recommend using numpy’s built-in eigensystem solvers
np.linalg.eigandnp.linalg.eigh
Your Answer: Complete the code belowPlot the eigenvalues of the data covariance matrix in descending order. What does this tell us about the effective dimensionality, and thus optimal number of features, to use to represent the von Karman dataset?
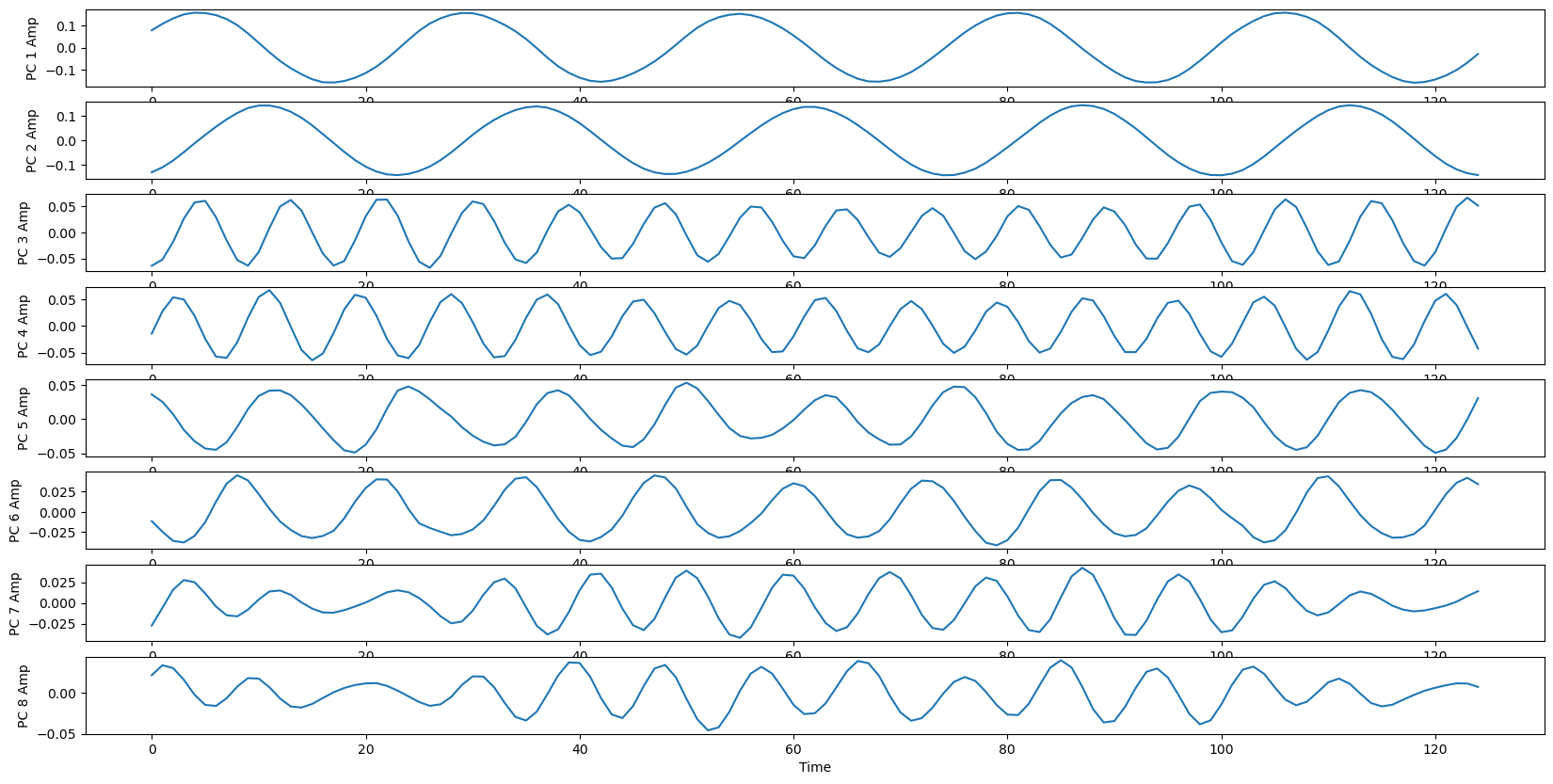
Your Answer: Try re-running your analysis using datasets from different Reynolds numbers. How does the effective dimensionality of the problem change as Reynolds number increases? How is that reflected in the lower-dimensional time series representation?
Your Answer: For this problem, the principal components often appear in pairs. Can you think of a reason for this?
Your Answer: What happens if we don’t subtract the feature-wise mean before calculating PCA? Why does this happen? You can answer this question empirically or theoretically.
Your Answer: In Fourier analysis, we project a function onto linear combination of trigonometric basis functions. How is this related to principal components analysis?
Your Answer: Load and explore the raw velocity field data¶
import os # Import the os module
import numpy as np # Import the numpy module
import urllib.request # Import requests module (downloads remote files)
Re = 300 # Reynolds number, change this to 300, 600, 900, 1200
fpath = f"../resources/von_karman_street/vortex_street_velocities_Re_{Re}.npz"
if not os.path.exists(fpath):
print("Data file not found, downloading now.")
print("If this fails, please download manually through your browser")
## Make a directory for the data file and then download to it
os.makedirs("../resources/von_karman_street/", exist_ok=True)
url = f'https://github.com/williamgilpin/cphy/raw/main/resources/von_karman_street/vortex_street_velocities_Re_{Re}.npz'
urllib.request.urlretrieve(url, fpath)
else:
print("Found existing data file, skipping download.")
vfield = np.load(fpath, allow_pickle=True).astype(np.float32) # Remove allow_pickle=True, as it's not a pickle file
print("Velocity field data has shape: {}".format(vfield.shape))
# Calculate the vorticity, which is the curl of the velocity field
vort_field = np.diff(vfield, axis=1)[..., :-1, 1] + np.diff(vfield, axis=2)[:, :-1, :, 0]
Found existing data file, skipping download.
Velocity field data has shape: (375, 128, 64, 2)
from matplotlib.animation import FuncAnimation
from IPython.display import HTML
plt.rcParams['animation.embed_limit'] = 2**26
# Assuming frames is a numpy array with shape (num_frames, height, width)
frames = vort_field.copy()[::4]
vmax = np.percentile(np.abs(frames), 98)
fig = plt.figure(figsize=(6, 6))
img = plt.imshow(frames[0], vmin=-vmax, vmax=vmax, cmap="RdBu")
plt.xticks([]); plt.yticks([])
# tight margins
plt.margins(0,0)
plt.gca().xaxis.set_major_locator(plt.NullLocator())
def update(frame):
img.set_array(frame)
ani = FuncAnimation(fig, update, frames=frames, interval=100)
HTML(ani.to_jshtml())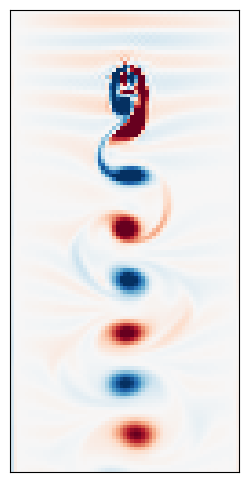
Implement principal component analysis¶
from sklearn.base import BaseEstimator, TransformerMixin
# We are going to use class inheritance to define our object. The two base classes from
# scikit-learn represent placeholder objects for working with datasets. They include
# many generic methods, like fetching parameters, getting the data shape, etc.
#
# By inheriting from these classes, we ensure that our object will have access to these
# functions, even though we didn't define them ourselves. Earlier in the course
# we saw examples where we defined our own template classes. Here, we are using the
# template classes define by the scikit-learn Python library.
class PrincipalComponents(BaseEstimator, TransformerMixin):
"""
A class for performing principal component analysis on a dataset.
Parameters
random_state (int): random seed for reproducibility
components_ (numpy array): the principal components
singular_values_ (numpy array): the singular values
"""
def __init__(self, random_state=None):
self.random_state = random_state
np.random.seed(self.random_state)
self.components_ = None
self.singular_values_ = None
def fit(self, X):
"""
Fit the PCA model to the data X. Store the eigenvectors in the attribute
self.components_ and the eigenvalues in the attribute self.singular_values_
NOTE: This method needs to return self in order to work properly with the
scikit-learn base classes from which it inherits.
Args:
X (np.ndarray): A 2D array of shape (n_samples, n_features) containing the
data to be fit.
Returns:
self (PrincipalComponents): The fitted object.
"""
########## YOUR CODE HERE ##########
#
# # YOUR CODE HERE
# # Hint: Keep track of whether you should be multiplying by a matrix or
# # its transpose.
#
########## YOUR CODE HERE ##########
raise NotImplementedError()
def transform(self, X):
"""
Transform the data X into the new basis using the PCA components.
Args:
X (np.ndarray): A 2D array of shape (n_samples, n_features) containing the
data to be transformed.
Returns:
X_new (np.ndarray): A 2D array of shape (n_samples, n_components) containing
the transformed data. n_components <= n_features, depending on whether
we truncated the eigensystem.
"""
########## YOUR CODE HERE ##########
#
# # YOUR CODE HERE
#
########## YOUR CODE HERE ##########
raise NotImplementedError()
def inverse_transform(self, X):
"""
Transform from principal components space back to the original space
Args:
X (np.ndarray): A 2D array of shape (n_samples, n_components) containing the
data to be transformed. n_components <= n_features, depending on whether
we truncated the eigensystem.
Returns:
X_new (np.ndarray): A 2D array of shape (n_samples, n_features) containing
the transformed data.
"""
########## YOUR CODE HERE ##########
#
# # YOUR CODE HERE
#
########## YOUR CODE HERE ##########
raise NotImplementedError()
## You shouldn't need to implement this, because it gets inherited from the base
## class. But if you are having trouble with the inheritance, you can uncomment
## this and to implement it.
# def fit_transform(self, X):
# self.fit(X)
# return self.transform(X)
Test and use your code¶
If you are working from a local fork of the entire course, then you already have access to the solutions. In this case, make sure to
git pullto make sure that you are up-to-date (save your work first).If you are working from a single downloaded notebook, or are working in Google Colab, then you will need to manually download the solutions file from the course repository. The lines below will do this for you.
data = np.copy(vort_field)[::3, ::2, ::2] # subsample data to reduce compute load
data = data.astype('float64') #Numpy linalg doesn't handle float16
data_reshaped = np.reshape(data, (data.shape[0], -1))
model = PrincipalComponents()
# model = PCA()
data_transformed = model.fit_transform(data_reshaped)
principal_components = np.reshape(
model.components_, (model.components_.shape[0], data.shape[1], data.shape[2])
)
## Look at skree plot, and identify the "elbow" indicating low dimensionality
plt.figure()
plt.plot(model.singular_values_[:50])
plt.plot(model.singular_values_[:50], '.')
plt.xlabel("Eigenvalue magnitude")
plt.ylabel("Eigenvalue rank")Running with Instructor Solutions. If you meant to run your own code, do not import from solutions
## Plot the principal components
plt.figure(figsize=(20, 10))
for i in range(8):
plt.subplot(1, 8, i+1)
vscale = np.percentile(np.abs(principal_components[i]), 99)
plt.imshow(principal_components[i], cmap="RdBu", vmin=-vscale, vmax=vscale)
plt.title("PC {}".format(i+1))
## Plot the movie projected onto the principal components
plt.figure(figsize=(20, 10))
for i in range(8):
plt.subplot(8, 1, i+1)
plt.plot(data_transformed[:, i])
plt.ylabel("PC {} Amp".format(i+1))
plt.xlabel("Time")
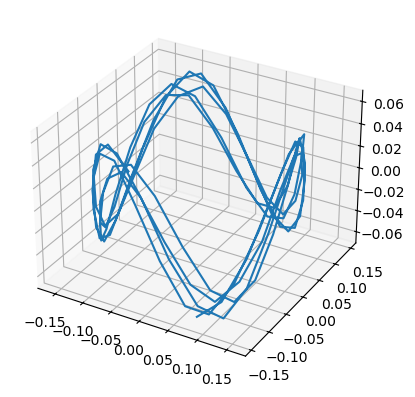
## Plot the time series against each other
plt.figure()
ax = plt.axes(projection='3d')
ax.plot(data_transformed[:, 0], data_transformed[:, 1], data_transformed[:, 2])[<mpl_toolkits.mplot3d.art3d.Line3D at 0x337c01d10>]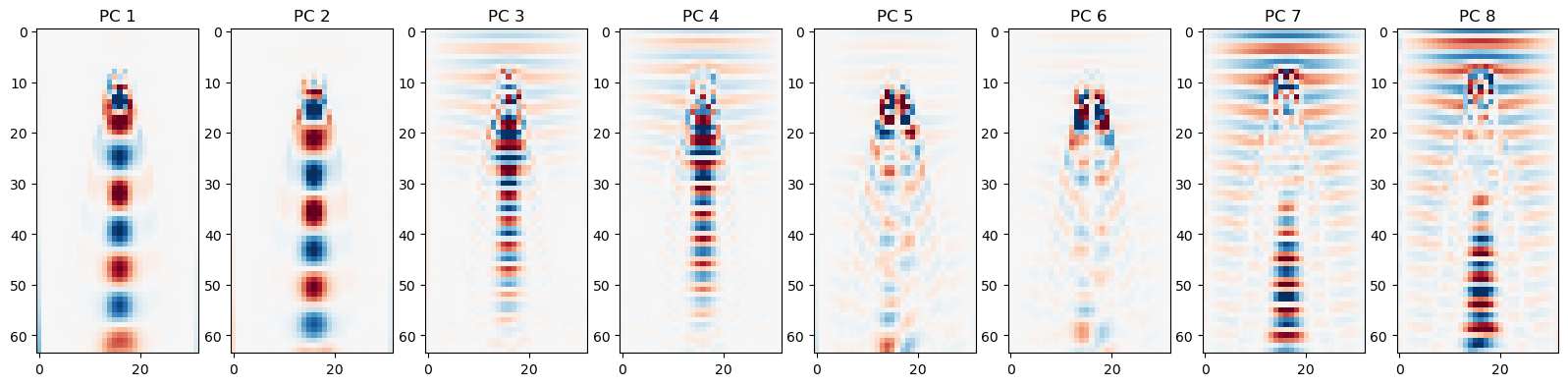
Follow-up ideas and additional information¶
We are applying PCA to sequences of velocity fields from a fluid flow, but this method can be applied to images, graphs, and almost any high-dimensional dataset. All that really matters is that you can take your data, and apply some sort of invertible transformation so that it becomes a big matrix of shape
The flow field we are studying was simulated using Lattice Boltzmann methods. In another module, we will learn how to numerically solve partial differential equations such as the Navier-Stokes equations that govern fluid flows. Lattice Boltzmann methods are distinct from the solvers we will use, however, because they involve simulating individual particles rather than a governing equation. LBM have significant similarity to the cellular automata we explored in previous modules.
What about the more general problem of finding new coordinates are that nonlinear functions of our observed features? One option would be to transform the data with fixed nonlinear functions that capture important features, such as trigonometric functions or spatially-localized kernels, and then apply the PCA calculation in this “lifted” space. This approach is the basis of kernel-PCA. Even more general approaches are the subject of current research in nonlinear embedding techniques, such as UMAP and tSNE.