We previously saw how to use the logistic map to model population growth. We saw that the logistic map can exhibit chaotic behavior |for certain values of the growth rate parameter . we will examine more closely how the behavior of the logistic map changes as we vary the parameter . We will use two different algorithms to probe the behavior of the logistic map as we vary the parameter : recursion and dynamic programming.
Preamble: Run the cells below to import the necessary Python packages

import numpy as np
# Import local plotting functions and in-notebook display functions
import matplotlib.pyplot as plt
%matplotlib inline
Re-implementing the logistic map with classes¶
First we will implement two classes: One that represents the logistic map, and one that calculates its bifurcation diagram. Unlike previous lectures, we will implement the Logistic map using an iterable class. This is a standalone class LogisticMap that stores the value of the growth rate parameter and the current position as instance attributes.
Special methods in Python classes: Python reserves certain method names for special purposes. For example, the __init__ method is automatically called when an object is created. The __call__ method allows an object to be treated like a function. In our implementation, we use the __call__ method to call the internal next method, which implements the actual recurrence relation defined by the logistic map. We also include a __str__ method. When we call print(map), Python understands that we want to print the string returned by the __str__ method.
class LogisticMap:
"""
Implements the logistic map.
Attributes:
r (float): The growth rate parameter
x (float): The current value of x for the logistic map.
"""
def __init__(self, r=3.8, x0=0.65):
self.r = r
self.x = x0
# def next(self):
# """Compute the next value of the map."""
# self.x = self.r * self.x * (1 - self.x)
# return self.x
def simulate(self, n):
"""Simulate the map for n iterations."""
x = []
for _ in range(n):
x.append(self()) # Notice that we can call the class like a function
return x
# The __call__ method allows us to call an instance of this class like a function.
# It must return the value that should be returned when the instance is called.
def __call__(self):
self.x = self.r * self.x * (1 - self.x)
return self.x
# The __str__ method is called when the object is printed. It must return a string.
def __str__(self):
return 'Logistic map with r = {:.2f}'.format(self.r)We can now simulate the logistic map by first initializing the class, and then calling the simulate method. We will simulate the map for 1000 iterations, and observe the chaotic behavior when is close to 4.
map = LogisticMap()
# # invoke the special __string__ method
print(map)
# # # # one step of the map
print(f"Initial condition: {map.x}")
print(f"First iteration: {map()}")
# # # plot the trajectory
traj = map.simulate(1000)
plt.figure(figsize=(9, 6))
plt.plot(traj)
plt.xlim(0, len(traj))
plt.xlabel('Iteration')
plt.ylabel('x')
Logistic map with r = 3.80
Initial condition: 0.65
First iteration: 0.8644999999999998
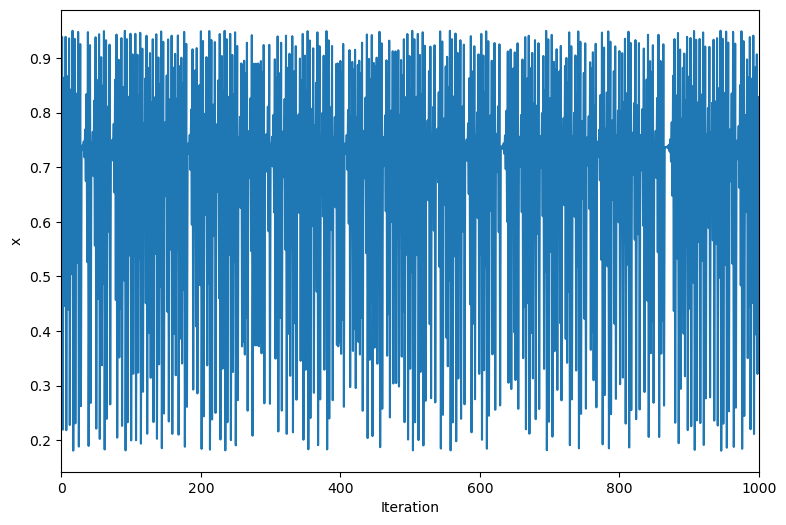
Bifurcation diagrams are used to visualize the behavior of a system as a function of a parameter. In a bifurcation diagram, we we vary a control parameter (like the growth rate in the case of the logistic map) and plot the long-term behavior of the system as a function of that parameter. In the case of the logistic map, the long-term behavior of the system is given by the number of unique values of observed after the transient has elapsed.
To implement a bifurcation diagram, we will implement an iterable class that iterates over a range of values of the parameter , and for each value of , simulates the logistic map for a fixed number of iterations. We will then return the last values of the trajectory after the transient has elapsed. Python has special syntax for objects that can be used in for loops, or implicitly in list comprehensions. An object is iterable if it has a special method called __iter__ that returns an object with a method called __next__. For our bifurcation diagram, we will use the __iter__ method to iterate over a range of values of , and the __next__ method to simulate the logistic map for a fixed number of iterations in order to calculate the unique map values for that value of .
class BifurcationDiagram:
"""
Find the bifurcation diagram for a map using __iter__ in Python. This stateful
implementation is more efficient than the stateless implementation we used previously,
because it does not need to store the entire trajectory in memory.
We will iterate over the map, one value of r at a time, and plot the last
values of x for each value of r after a transient has elapsed
Attributes:
dmap (callable): A discrete map object. Must contain a simulate method that returns a
trajectory of the map.
rmin (float): The minimum value of r to use.
rmax (float): The maximum value of r to use.
rsteps (int): The number of steps to take between rmin and rmax.
n (int): The number of iterations to use for each value of r.
transient (int): The number of iterations to discard as transient.
"""
def __init__(self, dmap, rmin, rmax, rsteps, n, transient=100):
self.dmap = dmap
self.rmin = rmin
self.rmax = rmax
self.rsteps = rsteps
self.n = n
self.transient = transient
# The __iter__ method tells Python that this class is iterable. It must return an
# object that implements the __next__ method. Iterable objects can be used in for
# loops and list comprehensions.
def __iter__(self):
return self
# The __next__ method is called by the for loop to get the next item in the
# iteration. It must return the next item, or raise StopIteration if there
# are no more items.
def __next__(self):
# Set map to use the current value of r
self.dmap.r = self.rmin
# Stop the calculation if we have reached the end of the parameter interval
if self.rmin > self.rmax:
raise StopIteration
## Otherwise, simulate the map for nsteps at the current value of r, and return
## the last values after the transient
else:
r = self.rmin
self.rmin += self.rsteps
return self.dmap.simulate(self.n)[self.transient:], r
Now that we have a working implementation of the logistic map, we can use it to explore the relationship between the growth rate and the long-term behavior of the system. We will use the BifurcationDiagram class to generate a bifurcation diagram for the logistic map. We will first instantiate a specific instance of the LogisticMap class, and then pass it to a specific instance of the BifurcationDiagram class stored in the variable diagram.
However, we don’t actually perform any calculations yet. We need to iterate over the diagram object to perform the calculations. We can do this using a for loop. At each call to the for loop, the __next__ method of the diagram object is called, which simulates the map for a fixed number of iterations at the current value of , and returns the last values of the trajectory after the transient has elapsed, as well as the current value of . We then immediately unpack the tuple returned by __next__ into the variables traj and r, and plot the trajectory against .
## Instantiate a bifurcation diagram for the logistic map
diagram = BifurcationDiagram(LogisticMap(), 2.4, 4.0, 0.001, 1000)
plt.figure(figsize=(9, 6))
# ## We can iterate over the diagram object itself to get the values of r and x
for traj, r in diagram:
plt.plot([r] * len(traj), traj, ',k', alpha=0.25)
# plt.xlabel('r')
# plt.ylabel('x')
# plt.xlim(2.4, 4.0)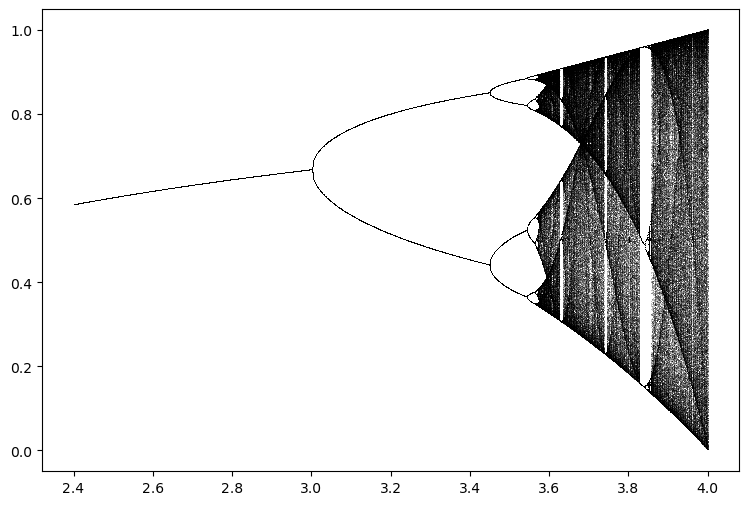
Lazy evaluation is a programming concept that means that a function or expression is not evaluated until its value is needed. In Python, lazy evaluation can be used to avoid unnecessary computation or memory allocation. In some database scenarios, lazy evaluation can be used to avoid reading data from disk until it is needed. Python has a built-in lazy evaluation mechanism called generators, but above we have implemented our own custom iterable class to illustrate the concept.
How often does the logistic map undergo period doubling?¶
When does the logistic map undergo period doubling? On the bifurcation diagram, we see that the period doubles at certain values of . Initially, these values are spaced pretty far apart in , but as we move to the right on the bifurcation diagram, the values of at which the period doubles appear to get closer and closer together. Is there any interesting structure in the spacing of these values of ?
We want to find these exact values of at which the period doubles. In the following sections, we will use a variety of search algorithms to localize the values of at which the period doubles.
Our code will consist of two parts:
A “check” function that compares trajectories at two different values of , and then determines whether the period of the logistic map doubled between them. This will take two trajectories corresponding to two different values of , and then estimate the number of unique values in the two trajectories. If the number of unique values is twice as large for the second trajectory as the first, we will return
True, indicating that the period has doubled. This function will thus return a boolean value.A “search” function that uses the “check” function to find the values of at which the period doubles. This function will return a list of values of at which the period doubles.
We will start by implementing the “check” function. Because we are working with a discrete map, we can simply compare the last few values of the two trajectories to determine whether the period has doubled. However, because we are working with floating point numbers, we need to be careful about the precision of the comparison. We thus implement a rounding function that truncates the trajectory to a certain number of decimal places.
def check_period_doubling(prev_traj, current_traj, tolerance=0.3):
"""
Check if the period has doubled from the previous trajectory to the current
trajectory. Uses a basic test of whether the number of unique values in the
current trajectory is greater than the number of unique values in the previous
trajectory.
Args:
prev_traj (array): Previous trajectory
current_traj (array): Current trajectory
tolerance (float): How close the period doubling ratio must be to 2 in order to
be considered a period doubling event.
Returns:
bool: True if period doubled, False otherwise
"""
# Round each trajectory to 4 decimal places to avoid numerical errors, and then
# count the number of unique values seen. A period 2 orbit will have 2 unique
# values, a period 4 orbit will have 4 unique values, and so on.
prev_unique_vals = len(np.unique(np.round(prev_traj, decimals=4)))
current_unique_vals = len(set(np.round(current_traj, decimals=4)))
# Check to see if the number of unique values has doubled, to within a threshold
has_doubled = np.abs(current_unique_vals / prev_unique_vals - 2) < tolerance
# has_doubled = (current_unique_vals == 2 * prev_unique_vals)
return has_doubledLine scanning¶
Our first search algorithm will be a simple “line scan” through the parameter space. We will take a range of evenly-spaced values between and , and for each value of , we will simulate the map for a fixed number of iterations. We will then check whether the period has doubled from the previous value of to the current value of . The cost of this search algorithm is where is the number of values we scan over. As its name implies, this algorithm thus has complexity, meaning that its runtime grows linearly with the number of decimal places we need to represent the values.
def line_scan(dmap, rmin, rmax, n_rvals=100, transient=50):
"""
Find the doubling points for a map using a line scan
Scan the values of r between rmin and rmax and find the values of r where the
map doubles in period. This function uses the discrete map's simulate method
to generate a trajectory for each value of r.
Args:
dmap (object): A discrete map object. Must contain a simulate method that
returns a trajectory of the map.
rmin (float): The minimum value of r to use.
rmax (float): The maximum value of r to use.
n_rvals (int): The number of values of r to use between rmin and rmax.
transient (int): The number of iterations to discard as transient.
Returns:
array: An array of values of r where the map doubles in period.
"""
## Create an array of r values to scan over
rvals = np.linspace(rmin, rmax, n_rvals)
doubling_rvals = []
prev_traj = None
for r in rvals:
## Set the parameter value and simulate the map in order to get a trajectory
dmap.r = r
traj = np.array(dmap.simulate(1000)[-transient:])
# If we have a previous trajectory, check for period doubling. If it
# has doubled, add the current value of r to the list of doubling r values
if prev_traj is not None:
if check_period_doubling(prev_traj, traj):
doubling_rvals.append(r)
## Update the previous trajectory
prev_traj = traj
return np.array(doubling_rvals)
import time
start = time.time()
rvals_c = line_scan(LogisticMap(), 2.4, 3.57, n_rvals=300)
print(rvals_c)
end = time.time()
print(f"Time elapsed: {end - start} seconds")
# # filter out values that change by less than 0.01
# rvals_c = rvals_c[:-1][np.diff(rvals_c) > (3.6 - 2.4) / (1000 - 1)]
# plt.figure()
# gaps = rvals_c[1:] - rvals_c[:-1]
# plt.plot(gaps)
# print(gaps[:-1] / gaps[1:])
# vals = [3.0]
# gap = 0.45252525
# for i in range(5):
# nxt = vals[-1] + gap
# vals.append(nxt)
# gap = gap / 4.667
# rvals_c = np.array(vals)
# gaps = rvals_c[1:] - rvals_c[:-1]
# plt.plot(gaps)[2.99869565 3.44869565 3.54652174 3.56608696]
Time elapsed: 0.04610419273376465 seconds
Now that we’ve found the period doubling values of , we can plot these values on top of the bifurcation diagram, to see whether they look right.
plt.figure(figsize=(9, 6))
## Create and plot the bifurcation diagram
diagram = BifurcationDiagram(LogisticMap(), 3.52, 3.58, 0.0001, 1000)
for traj, r in diagram:
plt.plot([r] * len(traj), traj, ',k', alpha=0.25)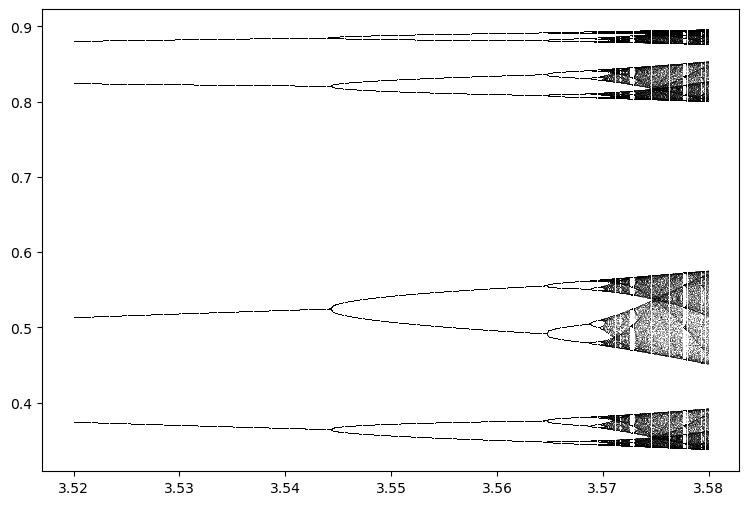
plt.figure(figsize=(9, 6))
## Create and plot the bifurcation diagram
diagram = BifurcationDiagram(LogisticMap(), 2.4, 4.0, 0.001, 1000)
for traj, r in diagram:
plt.plot([r] * len(traj), traj, ',k', alpha=0.25)
## Draw vertical lines at the period doubling points we found
for r in rvals_c:
plt.axvline(r, color='r', alpha=0.5)
plt.xlabel('r')
plt.ylabel('x')
# plt.xlim(2.4, 3.6)
plt.xlim(2.8, 3.6)(2.8, 3.6)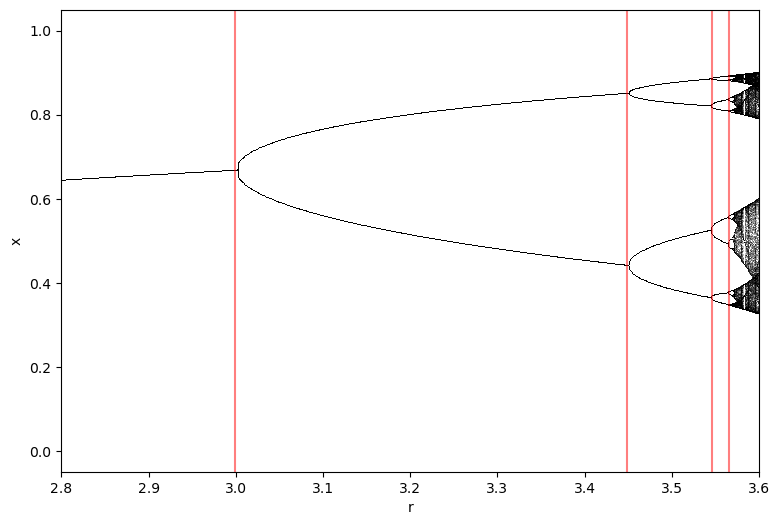
How are these doubling events distributed? We will plot the gaps (in ) between successive doubling events to see if they follow a pattern.
# filter out values that change by less than 0.01
# rvals_c = rvals_c[:-1][np.diff(rvals_c) > (3.6 - 2.4) / (10000 - 1)]
plt.figure()
gaps = rvals_c[1:] - rvals_c[:-1]
plt.xlabel('Doubling event index')
# in latex r_c
plt.ylabel('$r^*_{i+1} - r^*_i$')
plt.semilogy(gaps, '.k', markersize=20)
plt.semilogy(gaps, '-k')
print(f"Ratios between successive doublings: {gaps[:-1] / gaps[1:]}")
Ratios between successive doublings: [4.6 5. ]
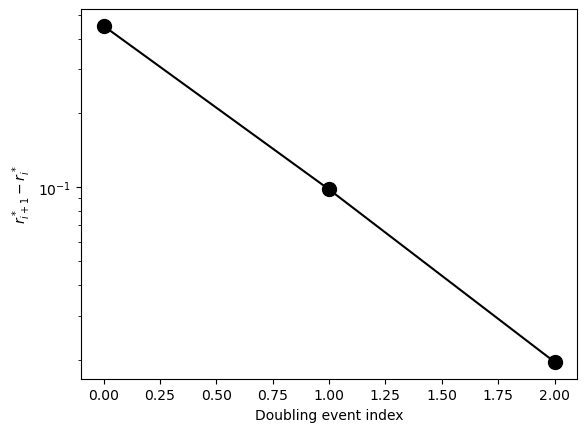
We can see that the spacing between successive doublings is decreasing as a power series, which roughly matches what we can see on the bifurcation diagram. However, we can see from looking at the bifurcation diagram that the localizations are not extremely accurate. Because a line scan densely samples the parameter space, the expected precision of the line scan is about , where is the number of values we scan over. So for the 1000 points we used here, we can expect about 3 decimal places of accuracy. We could thus say that a line scan has scaling of precision.
Binary search¶
A binary search is a search algorithm that works on a sorted list or array. Rather than checking each element in the list, binary search exploits the sorted structure to ignore large parts of the list in each iteration. At each iteration, we check the middle element of the list, and then recursively search only the left or right half of the list, depending on whether the doubling event occurs in that half.
Binary search has runtime cost because it cuts the list in half each time. It thus gains a digit of precision in the search for each iteration.
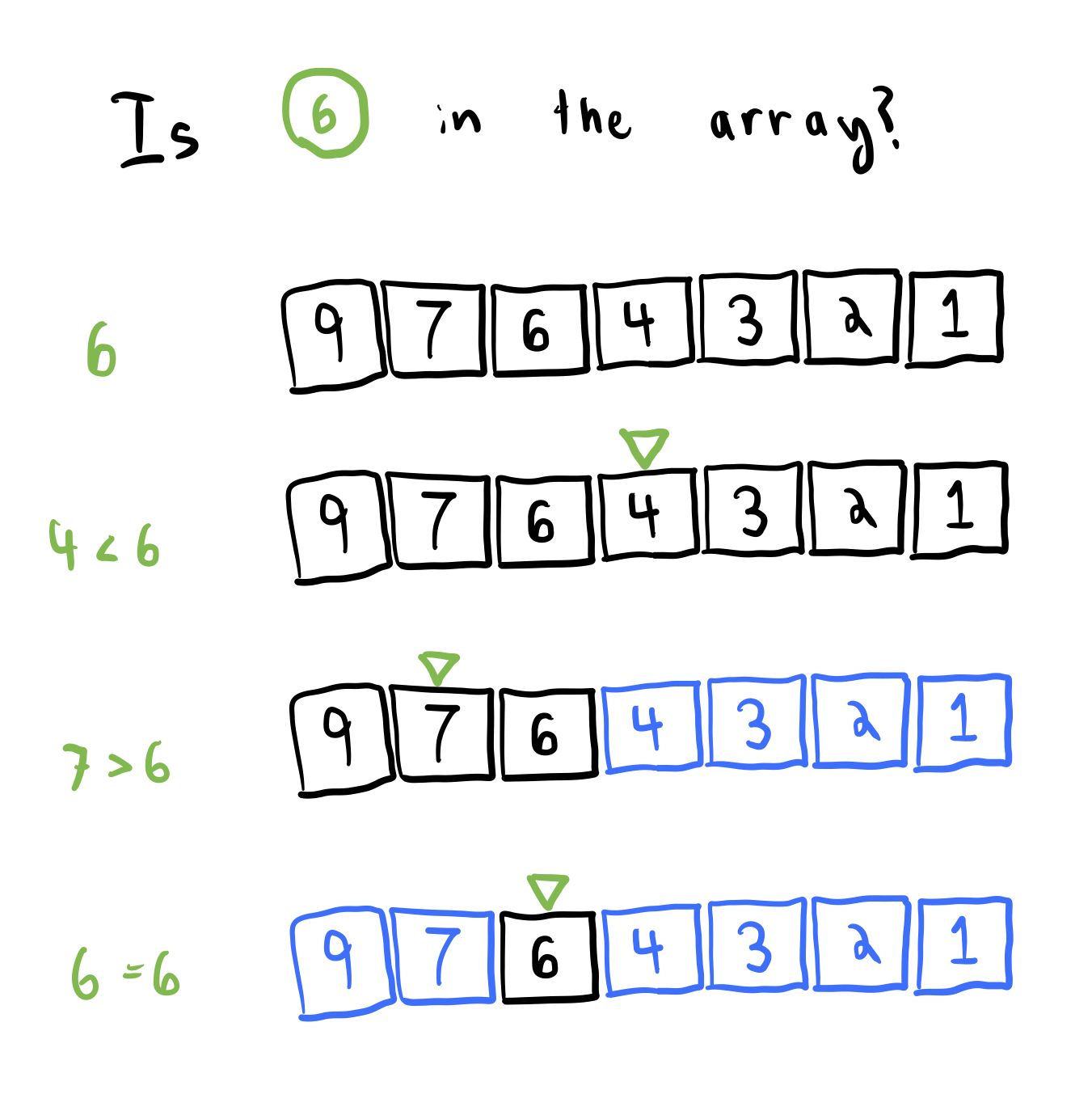
To implement a standard binary search on a sorted array, we use a two-pointer approach. We initialize two variables (pointers) corresponding to the index of the first and last elements of the array. At each iteration, we use the two pointers to find the middle index of the array. If the value at the middle index is greater than the target, we move the right pointer to the middle index. Otherwise, we move the left pointer to the middle index. We repeat this process until the left and right pointers meet. The index of the left pointer is the index of the first element greater than or equal to the target.
def binary_search(a, target):
"""
Find the index of the first element in a *sorted* array that is greater than or
equal to the target.
We are using a two-pointer approach where one pointer is always greater than the
target and the other is always less than the target. The pointers start at the ends
of the array and move towards each other until they meet. The index of the left
pointer is the index of the first element greater than or equal to the target.
Args:
a (array): A sorted array of numbers.
target (float): The target value to search for.
Returns:
int: The index of the first element greater than or equal to target.
"""
lo = 0
hi = len(a)
while lo < hi:
mid = (lo + hi) // 2
if a[mid] < target:
lo = mid + 1
else:
hi = mid
return lo
a = np.array([1, 2, 3, 4, 7, 8, 9, 10, 15, 43, 99])
print(binary_search(a, 5))4
Determining Big-O for an algorithm¶
Big-O notation is a way to describe the runtime and memory complexity of an algorithm. It describes how the runtime of an algorithm scales with the size of the input. For example, if an algorithm takes 1000 time steps to run on a problem of size , then a linear scaling algorithm () will take 2000 time steps to run on a problem of size . A quadratic scaling algorithm () will take 40000 time steps to run on a problem of size .
Usually, when estimating the “Big-O” of an algorithm, we are interested in the worst-case runtime. This is the maximum amount of time the algorithm will take to run on any input of size . However, there is often an ambiguity regarding the definition of . It can be the total number of particles, total number of mesh points, total number of time steps. It usually corresponds to an extensive quantity or resolution parameter.
In practice, the Big-O scaling of an algorithm is almost always some combination of a polynomial and . However, certain minimal operations, such as overwriting values, peeking the front of a queue, etc take constant time ().
There are some useful Big-O times to know:
Logarithmic scaling () usually means you can quickly rule out large parts the problem without directly looking at the associated values. This case arises in algorithms like recursion, bisection search, etc.
Exponential scaling () implies a combinatoric explosion as the number of inputs increases, such as a process that branches. This is usually not optimal, but some problems are inherently exponential. An example is the traveling salesman problem, or finding the global ground state of a set of randomly-coupled Ising spins.
Stirling’s approximation: or
Sorting a list via mergesort is
Binary search, two-sum are pointers with time
Dot product of two length- vectors is . matrix-vector product is . Product of two matrices is
import timeit
nvals = np.arange(2, 800)
nvals = np.arange(2, 5000, 3)
all_times = list()
for n in nvals:
all_reps = list()
all_times.append(
timeit.timeit(
"binary_search(np.arange(n), n // 2)", globals=globals(), number=10000
)
)
plt.figure(figsize=(9, 6))
plt.plot(nvals, all_times, 'k')
plt.xlabel('n')
plt.ylabel('Time (s)')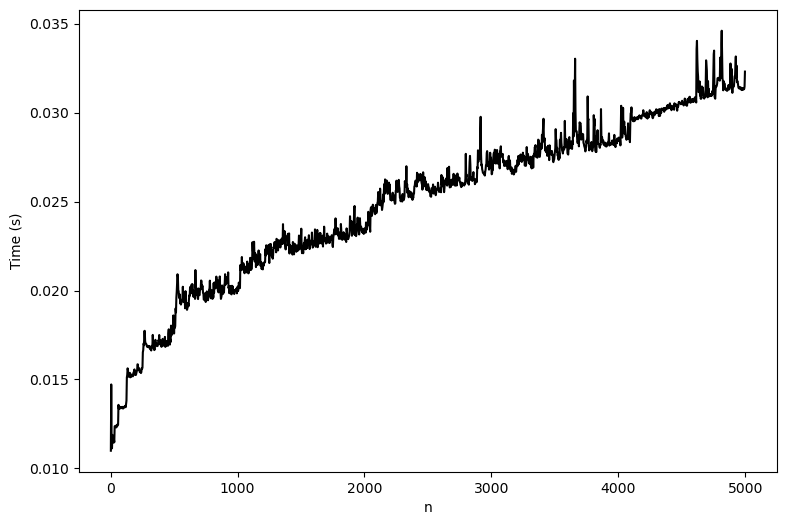
We can see that the runtime of binary search is . This is because the algorithm cuts the size of the list in half each time. Since the list is already sorted, we are able to quickly rule out half of the input each time we make a comparison, thus sparing us the cost of checking each element in the list, unlike the linear scan.
Calculation periodic doubling values in the logistic map with binary search¶
Now let’s return to our logistic map example. We will use a binary search to find the values of at which the period doubles. Because binary search avoids scanning many parameter values, we can avoid many intermediate values of between the doubling events.
Implementing binary search for period doubling¶
There a are a few nuances to our approach, compared to traditional binary search.
We need to perform a three-pointer comparison among the periods of the logistic map at , , and . This is because we are searching on a continuous parameter space. We thus implement a three-way comparison function, which requires three trajectories at three different values of to be passed in, and identifies if the period doubles between the first and second trajectories, or the second and third trajectories.
We need to find all values of corresponding to critical doubling values, rather than just one value. This requires multiple binary searches over different intervals, as well as a heuristic for modifying the intervals to ensure that we don’t repeatedly find the same root. We break down this process as follows:
a. We start by searching the full interval for the first doubling value.
b. Upon finding a doubling value, we shrink the interval so that the rightmost pointer is just below the root we just found by some tolerance .
c. We search the new interval for the next doubling value, and repeat the process.
This heuristic will fail if the period doubling values are closer than apart. In this case, we would need to reduce and try again. This same difficulty arises in methods used to find multiple roots (zero crossings) of continuous functions.
## Three-way comparison function
def check_period_doubling2(left_traj, middle_traj, right_traj):
"""
Check if the period doubles between right_traj and middle_traj
Functions by testing whether the number of unique values in the current trajectory
is greater than the number of unique values in the previous trajectory.
Args:
prev_traj (array): Previous trajectory
current_traj (array): Current trajectory
threshold (float): A threshold value to determine the similarity between points
Returns:
bool: True if period doubled, False otherwise
"""
## For each trajectory, count the number of unique values, to see what the period is
t_left = len(set(np.round(left_traj, decimals=4)))
t_middle = len(set(np.round(middle_traj, decimals=4)))
t_right = len(set(np.round(right_traj, decimals=4)))
## Check to see if the period has doubled by comparing the ratios of the number of
## unique values in the trajectories
factor_right = t_middle / t_left
factor_left = t_right / t_middle
return factor_right > factor_left
def binary_search_between(dmap, rmin, rmax, transient=50, tol=1e-6):
"""
Find a doubling between rmin and rmax using a binary search
Scan the values of r between rmin and rmax and find the values of r where the
map doubles in period. This function uses the discrete map's simulate method
to generate a trajectory for each value of r.
Args:
dmap (object): A discrete map object. Must contain a simulate method that
returns a trajectory of the map.
rmin (float): The minimum value of r to use.
rmax (float): The maximum value of r to use.
transient (int): The number of iterations to discard as transient.
tol (float): The tolerance for the binary search.
Returns:
float: The value of r where the map doubles in period.
"""
# print(f"Searching between {rmin} and {rmax}")
while rmax - rmin > tol:
rmid = (rmax + rmin) / 2
## Simulate the logistic map at the minimum, middle, and maximum values of r
dmap.__init__(r=rmin)
traj_min = np.array(dmap.simulate(1000)[-transient:])
dmap.__init__(r=rmid)
traj_mid = np.array(dmap.simulate(1000)[-transient:])
dmap.__init__(r=rmax)
traj_max = np.array(dmap.simulate(1000)[-transient:])
## If the period has doubled between the middle and maximum values of r, set
## rmin to rmid. Otherwise, set rmin to rmid.
where_double = check_period_doubling2(traj_min, traj_mid, traj_max)
if where_double:
rmax = rmid
else:
rmin = rmid
return rmid
def binary_search_bifurcation(dmap, rmin, rmax, n_iter, transient=50):
"""
Find doublings using a multipointer binary search
Scan the values of r between rmin and rmax and find the values of r where the
map doubles in period. This function uses the discrete map's simulate method
to generate a trajectory for each value of r.
Args:
dmap (object): A discrete map object. Must contain a simulate method that
returns a trajectory of the map.
rmin (float): The minimum value of r to use.
rmax (float): The maximum value of r to use.
n_iter (int): The number of iterations to use for each value of r.
transient (int): The number of iterations to discard as transient.
Returns:
array: An array of values of r where the map period doubles
"""
rvals = []
# narrow down the search between every pair of successive pointers to find a doubling
for i in range(n_iter):
rmax_new = binary_search_between(dmap, rmin, rmax, transient=transient)
if np.abs(rmax - rmax_new) < 1e-3:
rmax -= 1e-4
else:
rvals.append(rmax)
rmax = rmax_new
return np.array(rvals)[::-1]
rvals_c = binary_search_bifurcation(LogisticMap(), 2.8, 3.6, 10, transient=50)
plt.figure()
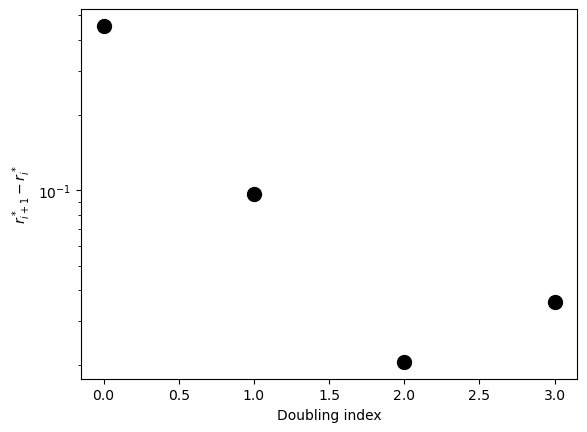
gaps = rvals_c[1:] - rvals_c[:-1]
plt.xlabel('Doubling index')
plt.ylabel('$r^*_{i+1} - r^*_i$')
plt.semilogy(gaps, '.k', markersize=20)
print(f"Ratios between successive doublings: {gaps[:-1] / gaps[1:]}")
Ratios between successive doublings: [4.67187821 4.69514424 0.57676821]
plt.figure(figsize=(9, 6))
## Create and plot the bifurcation diagram
diagram = BifurcationDiagram(LogisticMap(), 2.4, 4.0, 0.001, 1000)
for traj, r in diagram:
plt.plot([r] * len(traj), traj, ',k', alpha=0.25)
## Draw vertical lines at the period doubling points we found
for r in rvals_c:
plt.axvline(r, color='r', alpha=0.5)
plt.xlabel('r')
plt.ylabel('x')
# plt.xlim(2.4, 3.6)
plt.xlim(2.8, 3.6)(2.8, 3.6)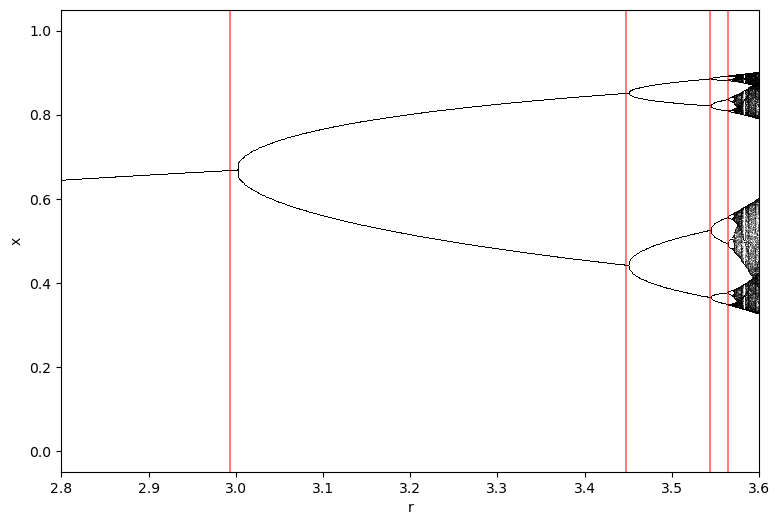
What’s going on physically?¶
Many chaotic systems approach chaos through a series of bifurcations, which occur at spacings on the bifurcation diagram equal to Feigenbaum’s constant. If is the parameter of the logistic map, and and are the critical parameter values of successive doubling bifurcations, then the ratio of successive bifurcation intervals approaches Feigenbaum’s constant:
The gap between successive doublings therefore decreases as a geometric series, with a ratio of . A geometric series decreasing by converges to a finite value, which here corresponds to the onset of chaos at in the logistic map.
The Feigenbaum constant is a universal constant, meaning that it is the same for all systems that exhibit period-doubling bifurcations. It was first measured in an experimental system by Libchaber & Maurer in 1986, who studied the period-doubling cascade in a Rayleigh-Bénard convection cell. This system consists of a thin layer of fluid heated from below, with convection rolls forming once the Rayleigh number exceeds a critical threshold. By carefully controlling the heating, they observed the onset of oscillatory instabilities, followed by a cascade of period-doubling bifurcations, eventually leading to turbulence.
Recursion and dynamic programming¶
For some problms, the solution to a size input can be written in terms of the previous , , etc. inputs. For example, the Fibonacci sequence: , with , . Problems of this form can be solved with recursion, which is a way of breaking a problem down into smaller and smaller pieces until you reach a limiting case
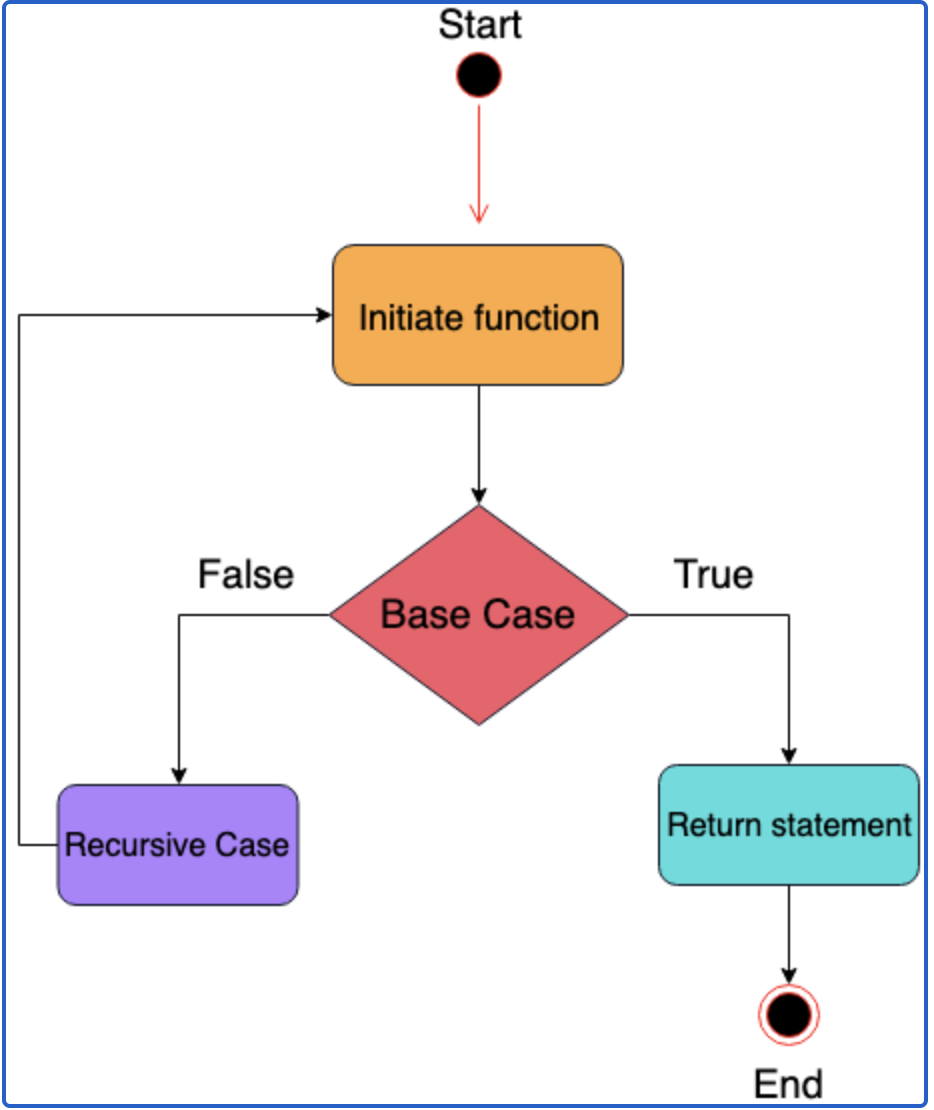
There are two key components to finding a recursive solution to a problem of size :
Inductive reasoning: We find a way to write any case for in terms of , , etc
Base cases: the limit of the problem when is small. For example, , (initial conditions), etc
Computing the factorial function¶
We will next implement two different approaches to computing the factorial function: recursion and dynamic programming.
Problem: Find
Inductive reasoning:
Base case:
def factorial(n):
"""Compute n factorial via recursion"""
# print(n, flush=True)
# Base case
if n == 0:
return 1
# Recursive case in which the function calls itself
else:
return n * factorial(n - 1) #+ factorial(n - 2)
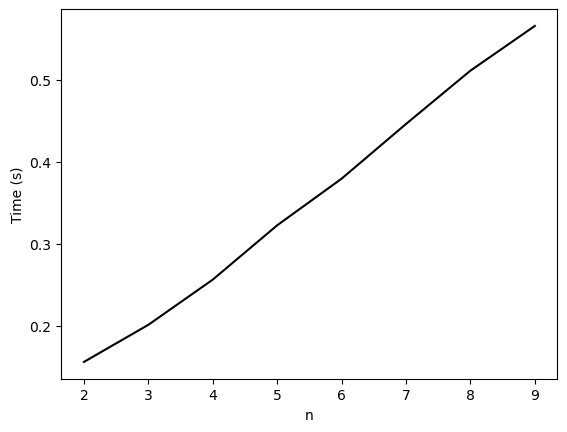
factorial(3)6We can estimate the runtime scaling of this function using the timeit utility.
### Run a timing test
import timeit
nvals = np.arange(2, 10)
all_times = list()
for n in nvals:
all_times.append(
timeit.timeit("factorial(n)", globals=globals(), number=1000000)
)
plt.figure()
plt.plot(nvals, all_times, 'k')
plt.xlabel('n')
plt.ylabel('Time (s)')
Instead of recursion, we can instead consider a bottom-up approach to the problem, which starts from the base case and builds up to the desired solution. This is called dynamic programming.
Problem: Find
Inductive reasoning:
Base case:
def factorial(n):
"""Compute n factorial, for n >= 0, with dynamic programming."""
# Start with base case
if n == 0:
return 1
nprev = 1
for i in range(1, n + 1):
# print(nprev, flush=True)
nprev *= i
# nprev = nprev * i
return nprev
factorial(4)6def factorial(n):
"""Compute n factorial, for n >= 0, with dynamic programming."""
# Start with base case
if n in [0, 1]:
return 1
nprev = 1
for i in range(2, n + 1):
nprev *= i
# nprev = nprev * i
return nprev
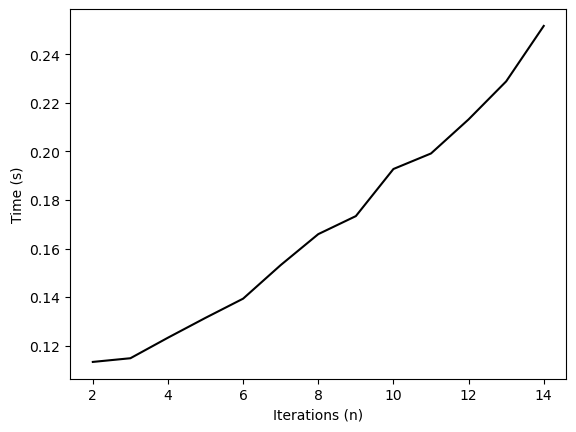
import timeit
nvals = np.arange(2, 15)
all_times = list()
for n in nvals:
all_times.append(
timeit.timeit("factorial(n)", globals=globals(), number=1000000)
)
plt.figure()
plt.plot(nvals, all_times, 'k')
plt.xlabel('Iterations (n)')
plt.ylabel('Time (s)')
Recursion vs Dynamic programming¶
Both recursion and dynamic programming use a “divide and conquer” approach, but they work in opposite directions. In recursion, we start from and work our way down to a base case. In dynamic programming, we start from the base case and work our way up to .
When working with graphs or trees, we often encounter recursion due to the need to perform depth-first search starting from a given node and continuing until a base case (like a leaf node) is reached. Conversely, in time-ordered processes, we often encounter dynamic programming due to the need to build up a solution from a base case (the initial conditions).
Dynamic programming is typically runtime, memory. Recursion is ideally runtime, but for exhaustive searches it can be runtime, memory because we can’t skip any steps
A subtlety of timing algorithms¶
Why did we only run timing tests of our factorial function for inputs up to ? What complicates our analysis if we try timing larger values of ?
import timeit
nvals = np.arange(2, 800)
all_times = list()
for n in nvals:
all_times.append(
timeit.timeit("factorial(n)", globals=globals(), number=10)
)
plt.figure()
plt.plot(nvals, all_times, 'k')
plt.xlabel('Iterations (n)')
plt.ylabel('Time (s)')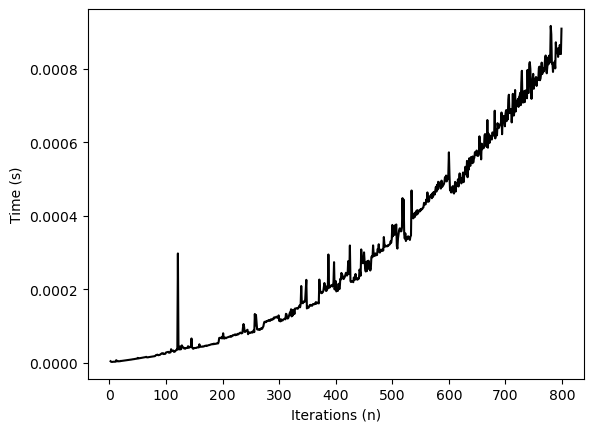
We naively expect that the runtime of our factorial function should scale linearly with . However, it turns out that multiplying large floats has unfavorable scaling with . Gradeschool multiplication is where is the number of digits, and Karatsuba multiplication is .
More recursion practice: The Fibonacci sequence¶
We next apply this approach to computing the Fibonacci sequence, which is famously defined by the recurrence relation
The first few Fibonacci numbers are
We can start by writing a recursive function to compute the Fibonacci sequence. The base cases are and .
def fibonacci(n):
"""Compute the nth Fibonacci number via recursion"""
# Base cases
if n == 0:
return 0
elif n == 1:
return 1
# Recursive case
else:
return fibonacci(n - 1) + fibonacci(n - 2)
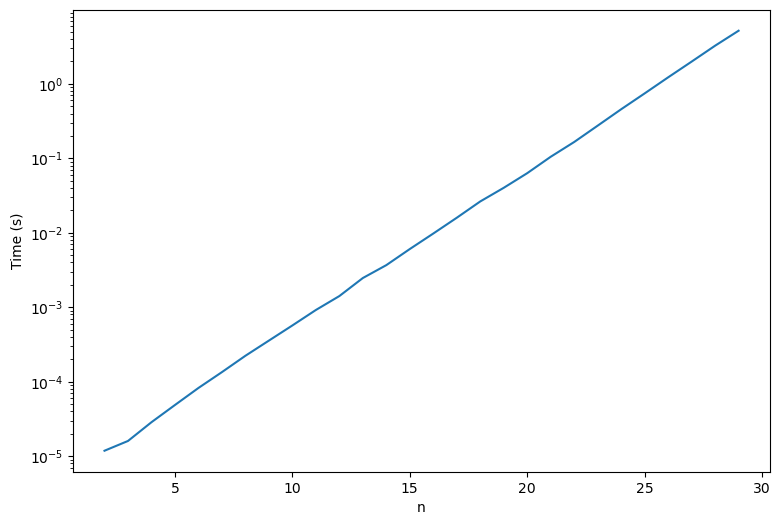
nvals = np.arange(2, 30)
all_times = list()
for n in nvals:
all_times.append(
timeit.timeit("fibonacci(n)", globals=globals(), number=10)
)
plt.figure(figsize=(9, 6))
plt.semilogy(nvals, all_times)
plt.xlabel("n")
plt.ylabel("Time (s)")
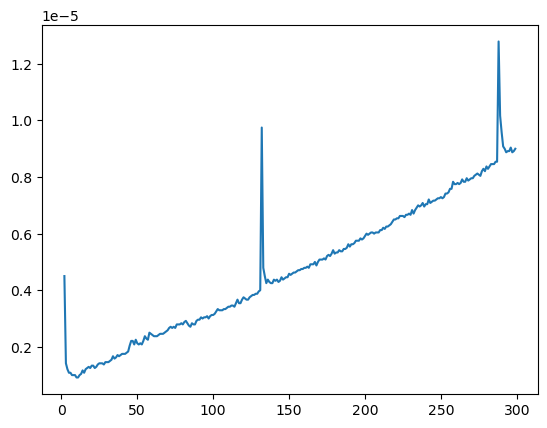
As before, the dynamic programming starts with the base cases and builds up to the solution.
def fibonacci(n):
"""Compute the nth Fibonacci number via dynamic programming."""
if n == 0:
return 0
elif n == 1:
return 1
n1, n2 = 0, 1
for i in range(2, n + 1):
n1, n2 = n2, n1 + n2
return n2
nvals = np.arange(2, 300)
all_times = list()
for n in nvals:
all_times.append(
timeit.timeit("fibonacci(n)", globals=globals(), number=1)
)
plt.plot(nvals, all_times)
Questions¶
Unlike the factorial function, the recursive approach is much slower than the dynamic programming approach, even though they both have the same asymptotic complexity. Why is this?
Recursion versus dynamic programming as discrete-time dynamical systems¶
We can also think of recursion and dynamic programming as dynamical systems. In this case, the input is the time variable, and the output is the state of the system at time .
For example, the factorial function can be written as the dynamical system
with initial condition .
The Fibonacci sequence can be written as the dynamical system
with initial conditions and .
Dynamic programming corresponds to simulating the dynamical system forward in time, starting from the initial condition. Recursion corresponds to simulating the dynamical system backward in time, starting from the final condition.
Recursion and dynamic programming: Depth-first search versus breadth-first search¶
Generally, recursion vs dynamic programming consists of two different “schema” for solving problems. In dynamic programming, we start from the base case and work our way up to the solution. In recursion, we start from the big case and then work our way down to the base case.
In both cases, the worst-case complexity is , where , are the number of vertices and edges, respectively. The number of edges of a hypercube is , where is the dimension. This implies a worst-case complexity for both dfs and bfs in a square lattice with vertices.
 >
>
Source: https://
 >
>
Source: https://
- Feigenbaum, M. J. (1978). Quantitative universality for a class of nonlinear transformations. Journal of Statistical Physics, 19(1), 25–52. 10.1007/bf01020332
- Libchaber, A., & Maurer, J. (1980). UNE EXPERIENCE DE RAYLEIGH-BENARD DE GEOMETRIE REDUITE ; MULTIPLICATION, ACCROCHAGE ET DEMULTIPLICATION DE FREQUENCES. Le Journal de Physique Colloques, 41(C3), C3-51-C3-56. 10.1051/jphyscol:1980309