You’ve likely encountered linear regression before in the context of fitting lines to data; it represents an interpretable “null hypothesis” model for finding trends in data. However, here we want to think a little more about how to interpret and understand linear regression, and so we will study a different context: learning approximate dynamical models directly from observations.
Preamble and imports
This notebook requires the following imports:
numpy
matplotlib
A note on cloud-hosted notebooks. If you are running a notebook on a cloud provider, such as Google Colab or CodeOcean, remember to save your work frequently. Cloud notebooks will occasionally restart after a fixed duration, crash, or prolonged inactivity, requiring you to re-run code.
Open this notebook in Google Colab: 
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inlineThe vortex street revisited¶
We’ve previously seen the von Karman vortex street in an earlier assignment. This fluid flow corresponds a uniform flow moving over a cylinder. The velocity scale of this system, , is set by the speed at which the fluid passes over the cylinder, while the length scale is the length of the cylinder. We normally see the vortex street instability first appear in the wake when . In our previous homework, we used a von Karman dataset comprising a series of snapshots of a two-dimensional velocity field, with separate datasets corresponding to different Reynolds numbers.
Suppose want to train a model that predicts the next snapshot of the flow field, , given only the current snapshot as an input. Our general learning problem has the form
where is the function that we are attempting to learn. While there are a variety of methods for learning the function , we will start by attempting to learn a linear model,
This problem is challenging because the Navier-Stokes equations are not linear in . In other words, by fitting a linear model to the snapshot time series, we attempt to approximate a highly nonlinear PDE with a linear model. We suspect that this approximation may work better over shorter timescales.
We can treat this problem as a regression problem, where our data matrix represents a stack of snapshots of the velocity field at different times, . While we are working with time series data, we will treat each snapshot as if it were an independent sample of a set of features---our regression results will be invariant to random shuffles of the input velocity field time series. In a more sophisticated approach, we might consider taking the ordering information into account in our regression. Our regression target, , represents the values of the velocity field at the next point in time, because our model will attempt to just predict the next step ahead in the process. For this reason, our labels or targets represent the matrix . We emphasize that this regression problem is identical to standard linear regression, where we predict an outcome based on a set of input features . Our forecasting problem is unique only in that and happen to have the same dimensionality, since they are snapshots of a velocity field.
There’s one hiccup in our approach: our input data is extremely high-dimensional. If we think of our input as a design matrix , then number of features is extremely large , because we have x- and y- velocity components on each site of an lattice. That means that we might find ourselves in the limit , in which case the problem is underdetermined: there are multiple values of that will maximize the accuracy of our model. As a tiebreaker, we will use the Ridge, or Tikhonov criterion: we select the solution parameter vector with the lowest norm.
Putting our goals together, we arrive at a loss function describing the problem that we want to solve,
where the first term is proportional to the mean squared error, and is a hyperparameter that determines how much we penalize the total weight vector. We wish to minimize this objective function with respect to the parameter matrix . This means that we want to solve the linear equation for . Note that while the loss function is a scalar, we are taking its derivative with respect to a tensor . After some linear algebra, we arrive at the following closed-form expression for the value of the weight vector
In the case , our problem reduces to the ordinary least-squares (OLS) formula. In the case where we have large numbers of features, the ridge penalty is necessary to ensure that our problem has a unique solution. Even if , we might still prefer to use ridge regression to ordinary least squares, because ridge regression favors more parsimonious solutions, that avoid excessively weighting certain features.
To Do¶
Please complete the following tasks and answer the included questions. You can edit a Markdown cell in Jupyter by double-clicking on it. To return the cell to its formatted form, press [Shift]+[Enter].
Starting from the optimality condition , derive the ridge regression formula shown above. You may find some of the linear algebra tricks from the matrix cookbook helpful here.
Your Answer: Implement a Ridge Regression model that predicts the next values of the Navier-Stokes equations. Below you will find three cells: one that loads the dataset, one that puts this dataset into a dataloader, and an unfinished class implementing Ridge regression. You only need to modify the RidgeRegression class, but you need to run the first two cells to load the data.
Note: If you are working from a fork of the full course repository, the dataset should load automatically because it is already on your computer. If not, the first cell below automatically downloads the datasets and places it in higher-level directory on your computer
../resources. If the automatic download fails, you may need to manually download the von Karman dataset and place it in the correct directory, one level above the directory containing this notebook.The
ForecastingDatasetclass implemented below will store and feed the data to our regression model. This object will handle creating train/val/test splits for you. For now, just implement the “global” solution method to the ridge regression problem. You can implement an iterative solution if you want a more challenging problem. You may find the Matrix Derivative Tutorial helpful for the iterative solution.
Your Answer: Complete the code belowYou’ll notice that the train/test split in the provided
ForecastingDatasetobject ensures that the test data occurs after the training data in the time series, and that no data points are repeated. Why do you think this is important for this problem?
Your Answer: Our model has a single hyperparameter, the regularizer strength , that determines the degree to which the weight entries in the regression matrix are penalized. Using the validation fold of our training dataset, find the best value of that hyperparameter. You can find placeholder code for this below.
Your Answer: complete the code belowRepeat your experiments using the von Karman datasets with different Reynolds numbers. How does forecast accuracy generally change with Reynolds number?
Your Answer: There are plenty of other ways to solve a regression problem, besides ridge regression. In the last code cells below, we use implementations of several regression models included in the Python package
scikit-learn. Check out how these models perform. Are there any surprises? Look up some background info on the models that seem to perform particularly well. Why do you think they work so well on this problem?
Your Answer: Optional Challenge Problem We are treating our forecasting problem like a black box regression problem---we seek to find a linear map between two vectors, which happen to be flattened snapshots of the velocity field. However, since we know that our problem is a fluid flow, we can exploit our domain knowledge to improve how our model sees the data---in the language of ML, we can improve our model with an “inductive bias.” From the numerical integration homework, we know that solving spatial PDEs involves calculating discrete Laplace operators, or taking the spatial Fourier transform. Using my code outlined below, implement a function that featurizes each snapshot of a velocity field array by adding spatial gradients and frequencies as features. Re-run your forecasting with this improved featurization of the data.
Your Answer: complete the code below
import os # Import the os module
import numpy as np # Import the numpy module
import urllib.request # Import requests module (downloads remote files)
Re = 300 # Reynolds number, change this to 300, 600, 900, 1200
fpath = f"../resources/von_karman_street/vortex_street_velocities_Re_{Re}.npz"
if not os.path.exists(fpath):
print("Data file not found, downloading now.")
print("If this fails, please download manually through your browser")
## Make a directory for the data file and then download to it
os.makedirs("../resources/von_karman_street/", exist_ok=True)
url = f'https://github.com/williamgilpin/cphy/raw/main/resources/von_karman_street/vortex_street_velocities_Re_{Re}.npz'
urllib.request.urlretrieve(url, fpath)
else:
print("Found existing data file, skipping download.")
vfield = np.load(fpath, allow_pickle=True).astype(np.float32) # Remove allow_pickle=True, as it's not a pickle file
print("Velocity field data has shape: {}".format(vfield.shape))
# Compute the velocity magnitude
vfield_mag = np.sqrt(vfield[..., 0]**2 + vfield[..., 1]**2)
n_tpts = vfield.shape[0]
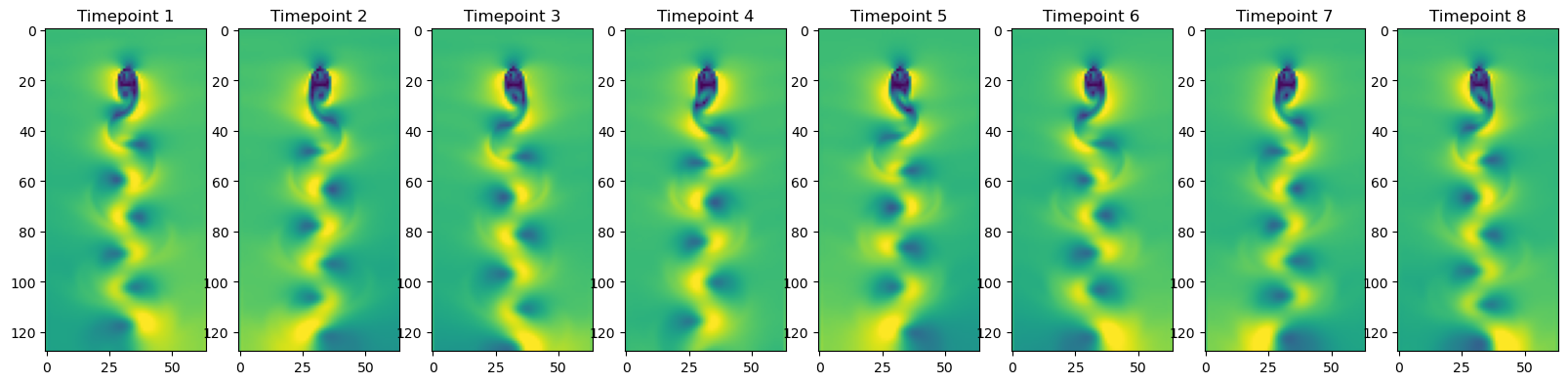
plt.figure(figsize=(20, 10))
for i in range(8):
plt.subplot(1, 8, i+1)
v_vals = vfield_mag[n_tpts // 8 * i]
plt.imshow(v_vals, cmap="viridis", vmin=0, vmax=np.percentile(v_vals, 99))
plt.title("Timepoint {}".format(i + 1))Found existing data file, skipping download.
Velocity field data has shape: (375, 128, 64, 2)
Load the forecasting dataset¶
This code loads the forecasting dataset and performs some basic utility functions, like splitting it into training and testing data.
class ForecastingDataset:
"""
A class for formatting time series data for forecasting.
By convention, time is assumed to be the first dimension of the dataset.
For time series data, it is very important that all data in test set is after
all data in the train and val sets. We also need to ensure that datapoints don't
appear in multiple splits.
Parameters
X (np.ndarray): The time series data. The first dimension is assumed to be time.
split_ratio (tuple): The ratio of the data to be used for train, val, and test.
forecast_horizon (int): The number of time steps to forecast at once
featurizer (callable): A function that takes in multivariate snapshot and
returns a feature vector. If None, the raw data is used.
"""
def __init__(self, X, split_ratio=(0.6, 0.2, 0.2), forecast_horizon=1, featurizer=None):
if featurizer is None:
self.featurizer = lambda x: x
else:
self.featurizer = featurizer
self.feature_shape = X.shape[1:]
# We need to ensure that datapoints don't appear in multiple splits, hence why
# we crop by the forecast horizon. We are going to do one-step forecasting
self.X_full = self.featurizer(X[:-1])#[:-forecast_horizon]
self.y_full = X[1:]#[forecast_horizon:]
self.forecast_horizon = forecast_horizon
# Split the data into train, val, test
n_train = int(len(self.X_full) * split_ratio[0])
n_val = int(len(self.X_full) * split_ratio[1])
n_test = len(self.X_full) - n_train - n_val
# Our frequent use of the forecast_horizon parameter again arises from our need
# to ensure that datapoints don't appear in multiple splits.
self.X_train, self.y_train = self.X_full[:n_train], self.y_full[:n_train]
self.X_val, self.y_val = (
self.X_full[n_train + forecast_horizon : n_train + forecast_horizon + n_val], # 1 - 600, 2 - 601 | 601 - 800
self.y_full[n_train+ forecast_horizon:n_train + forecast_horizon + n_val]
)
self.X_test, self.y_test = (
self.X_full[n_train + 2 * forecast_horizon+ n_val:],
self.y_full[n_train + 2 * forecast_horizon + n_val:]
)
def __len__(self):
return len(self.X_full)
def __getitem__(self, idx):
return self.X_full[idx], self.y_full[idx]
def flatten_data(self, x):
"""
Given a dataset, transform into a flat feature form
"""
return np.reshape(x, (x.shape[0], -1))
def unflatten_data(self, x):
"""
Given a flat dataset, convert back to the original shape
"""
out = np.reshape(x, (x.shape[0], *self.feature_shape))
return out
# Let's do a simple unit test to make sure that our class is working as expected
# Take some time to understand what these test cases cover
import unittest
class TestForecastingDataset(unittest.TestCase):
def test_initialization(self):
fd = ForecastingDataset(np.arange(100)[:, None])
assert fd.y_train[0] == fd.X_train[1], "y_train is not shifted by 1 from X_train"
assert fd.y_val[0] == fd.X_val[1], "y_val is not shifted by 1 from X_val"
assert fd.y_test[0] == fd.X_test[1], "y_test is not shifted by 1 from X_test"
assert fd.y_train[-1] < fd.y_val[0], "y_train and y_test are not disjoint"
assert fd.y_val[-1] < fd.y_test[0], "y_val and y_test are not disjoint"
# test split_size
unittest.main(argv=[''], exit=False);
.
----------------------------------------------------------------------
Ran 1 test in 0.000s
OK
Implement the Ridge regression model¶
import numpy as np
import warnings
import matplotlib.pyplot as plt
class BaseRegressor:
"""
A base class for regression models.
"""
def __init__(self):
self.weights = None
self.bias = None
def fit(self, X, y):
"""
Fits the model to the data.
"""
raise NotImplementedError("Subclasses must implement this method")
def predict(self, X):
raise NotImplementedError("Subclasses must implement this method")
def score(self, X, y):
"""
Returns the mean squared error of the model.
"""
return np.mean((self.predict(X) - y)**2)
class LinearRegressor(BaseRegressor):
"""
A linear regression model is a linear function of the form:
y = w0 + w1 * x1 + w2 * x2 + ... + wn * xn
The weights are the coefficients of the linear function.
The bias is the constant term w0 of the linear function.
Attributes:
method: str, optional. The method to use for fitting the model.
regularization: str, optional. The type of regularization to use.
"""
def __init__(self, method="global", regularization="ridge", regstrength=0.1, **kwargs):
super().__init__(**kwargs)
self.method = method
self.regularization = regularization
self.regstrength = regstrength
# functions that begin with underscores are private, by convention.
# Technically we could access them from outside the class, but we should
# not do that because they can be changed or removed at any time.
def _fit_global(self, X, y):
"""
Fits the model using the global least squares method.
"""
############################################################
#
#
# YOUR CODE HERE
#
#
############################################################
raise NotImplementedError
def _fit_iterative(self, X, y, learning_rate=0.01):
"""
Fit the model using gradient descent.
"""
############################################################
#
#
# YOUR CODE HERE
#
#
############################################################
raise NotImplementedError
def fit(self, X, y):
"""
Fits the model to the data. The method used is determined by the
`method` attribute.
"""
############################################################
#
#
# YOUR CODE HERE. If you implement the _fit_iterative method, be sure to include
# the logic to choose between the global and iterative methods.
#
#
############################################################
raise NotImplementedError
def predict(self, X):
return X @ self.weights + self.bias
Test your solution¶
You don’t need to write any new code below here. This is all to test your solution and study its properties.
# Automatically split the data into train, validation, and test sets
dataset= ForecastingDataset(vfield_mag)
# Initialize the model
model = LinearRegressor(method="global", regularization="ridge", regstrength=1.0)
model.fit(
dataset.flatten_data(dataset.X_train),
dataset.flatten_data(dataset.y_train)
)
y_test_pred = dataset.unflatten_data(
model.predict(dataset.flatten_data(dataset.X_test))
)
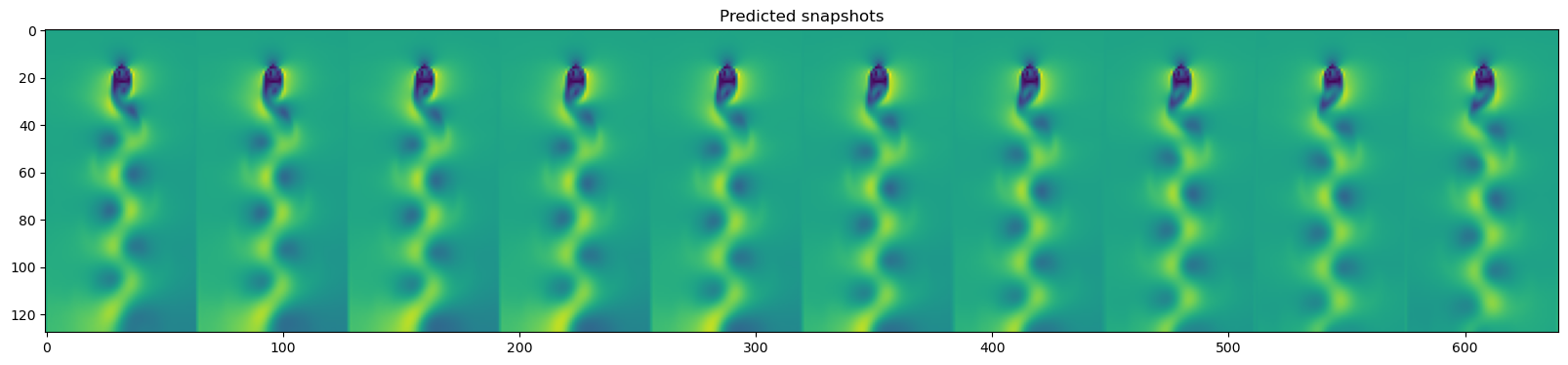
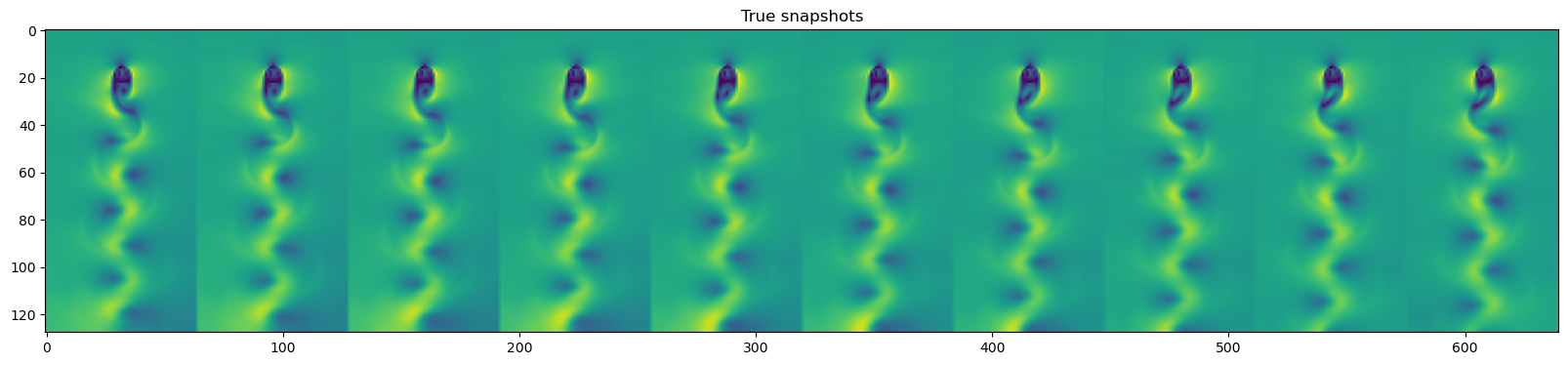
plt.figure(figsize=(20, 10))
plt.imshow(np.hstack(y_test_pred[::3][-10:]))
plt.title("Predicted snapshots")
plt.figure(figsize=(20, 10))
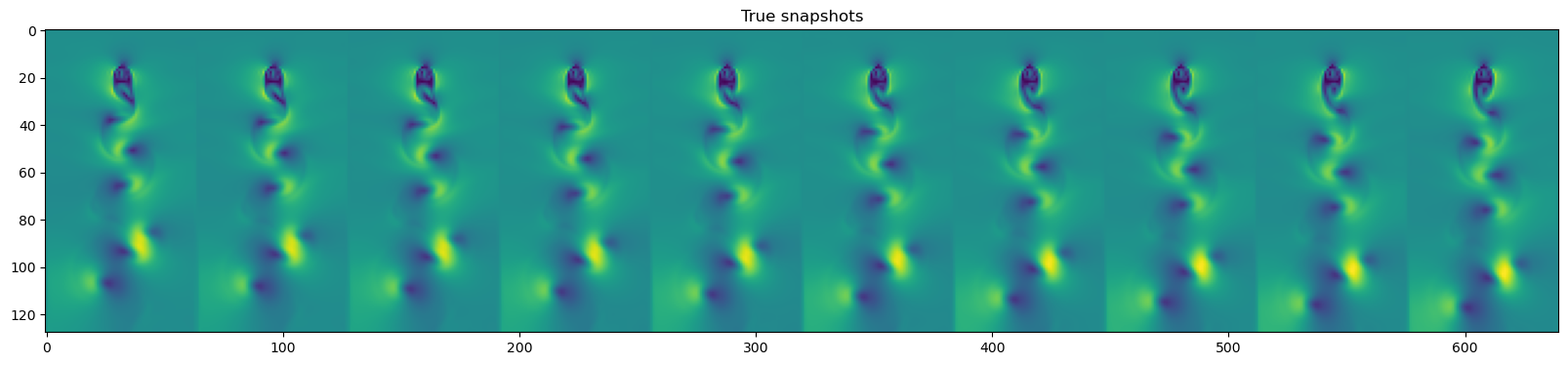
plt.imshow(np.hstack(dataset.y_test[::3][-10:]))
plt.title("True snapshots")
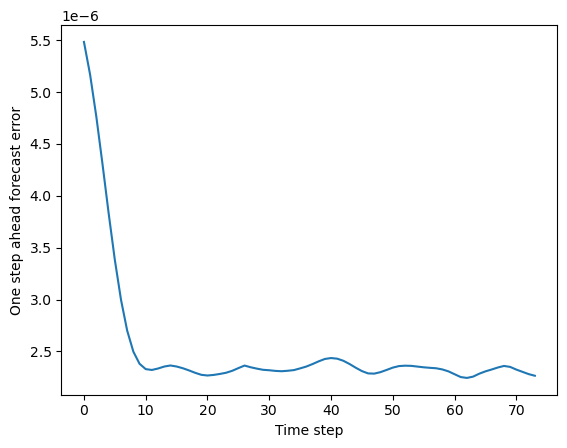
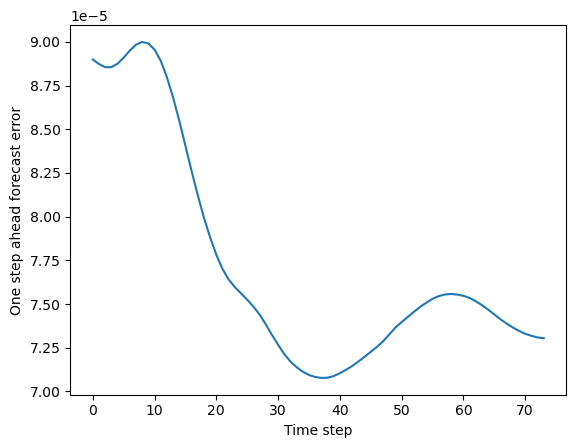
mse_vs_time = np.mean((y_test_pred - dataset.y_test)**2, axis=(1, 2))
plt.figure()
plt.plot(mse_vs_time)
plt.ylabel("One step ahead forecast error")
plt.xlabel("Time step")
Running with Instructor Solutions. If you meant to run your own code, do not import from solutions
Perform hyperparameter tuning¶
Using the validation fold of the von Karman dataset, find the best value of the ridge penalty hyperparameter .
## Set the range of regularizer strengths that we want to check
regstrengths = np.logspace(-4, 4, 9)
all_mse = []
for regstrength in regstrengths:
print(f"Training model with regstrength={regstrength}", flush=True)
model = LinearRegressor(method="global", regularization="ridge", regstrength=regstrength)
model.fit(
dataset.flatten_data(dataset.X_train),
dataset.flatten_data(dataset.y_train)
)
y_val_pred = dataset.unflatten_data(
model.predict(dataset.flatten_data(dataset.X_val))
)
mse = np.mean((y_val_pred - dataset.y_val)**2)
all_mse.append(mse)
best_regstrength = regstrengths[np.argmin(np.array(all_mse))]
print(f"Best regularize strength: {best_regstrength}")
Training model with regstrength=0.0001
Training model with regstrength=0.001
Training model with regstrength=0.01
Training model with regstrength=0.1
Training model with regstrength=1.0
Training model with regstrength=10.0
Training model with regstrength=100.0
Training model with regstrength=1000.0
Training model with regstrength=10000.0
Best regularize strength: 0.1
model = LinearRegressor(method="global", regularization="ridge", regstrength=best_regstrength)
model.fit(
dataset.flatten_data(dataset.X_train),
dataset.flatten_data(dataset.y_train)
)
y_test_pred = dataset.unflatten_data(
model.predict(dataset.flatten_data(dataset.X_test))
)
plt.figure(figsize=(20, 10))
plt.imshow(np.hstack(y_test_pred[::3][-10:]))
plt.title("Predicted snapshots")
plt.figure(figsize=(20, 10))
plt.imshow(np.hstack(dataset.y_test[::3][-10:]))
plt.title("True snapshots")
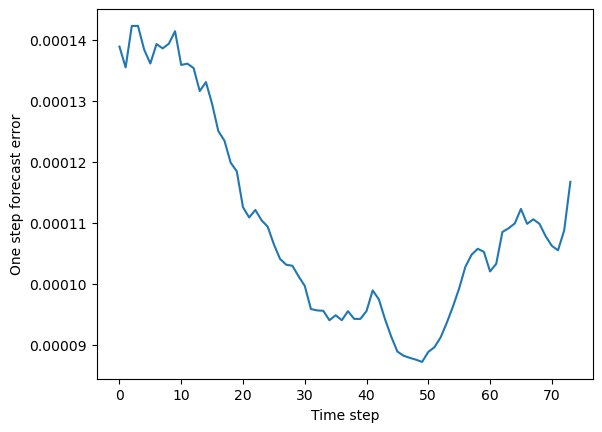
mse_vs_time = np.mean((y_test_pred - dataset.y_test)**2, axis=(1, 2))
plt.figure()
plt.plot(mse_vs_time)
plt.ylabel("One step ahead forecast error")
plt.xlabel("Time step")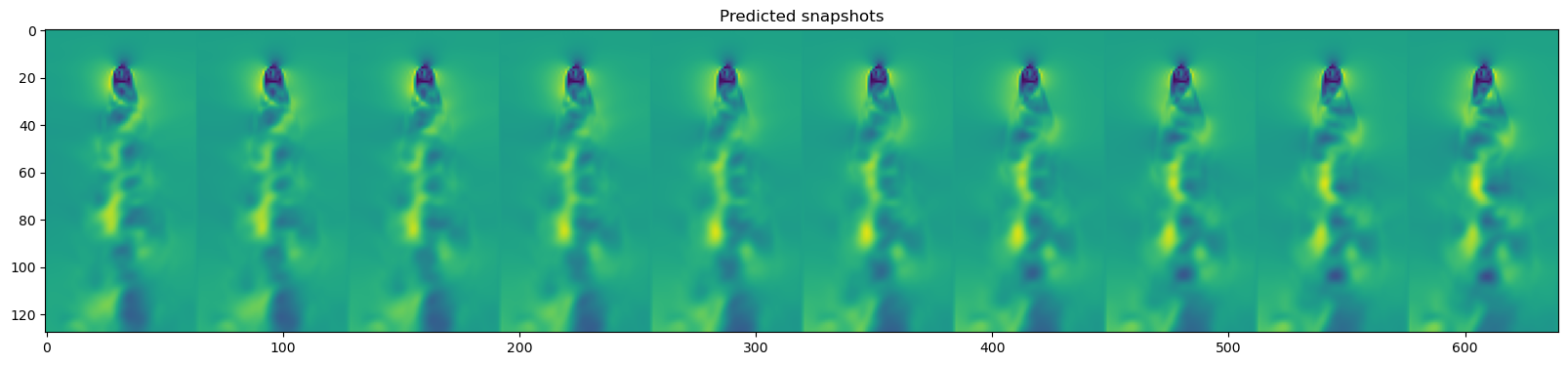
Optional: Improve the featurization of the velocity field dataset¶
Use domain knowledge to calculate nonlinear features of the velocity field, and see if you can get better results for linear regression.
def featurize_flowfield(field):
"""
Compute features of a 2D spatial field. These features are chosen based on the
intuition that the input field is a 2D spatial field with time translation
invariance.
The output is an augmented feature along the last axis of the input field.
Args:
field (np.ndarray): A 3D array of shape (batch, nx, ny) containing the flow
field. The "batch" axis corresponds to time or an arbitrary flow field
snapshot index, if you shuffled the data.
Returns:
field_features (np.ndarray): An array of shape (batch, nx, ny, M) containing
the additional computed features stacked along the last axis
"""
############################################################################
#
#
# YOUR CODE HERE
# Hint: I used concatenate to combine the features together. You have some choice of
# which features to include, but make sure that your features are computed
# separately for each batch element: for each flow field snapshot, they take an
# N x N x 2 vector field and return a N x N x D vector field, where D is any integer.
# My implementation is vectorized along the first (batch) axis
#
############################################################################
raise NotImplementedError
## Import William's solutions
# from solutions.linear_regression import featurize_flowfield
## Pass the data through the featurizer using the keyword argument
dataset = ForecastingDataset(vfield_mag, featurizer=featurize_flowfield)
# dataset = ForecastingDataset(vfield_mag, featurizer=None)
## Initialize the model
model = LinearRegressor(method="global", regularization="ridge", regstrength=0.1)
model.fit(
dataset.flatten_data(dataset.X_train),
dataset.flatten_data(dataset.y_train)
)
y_test_pred = dataset.unflatten_data(
model.predict(
dataset.flatten_data(dataset.X_test)
)
)
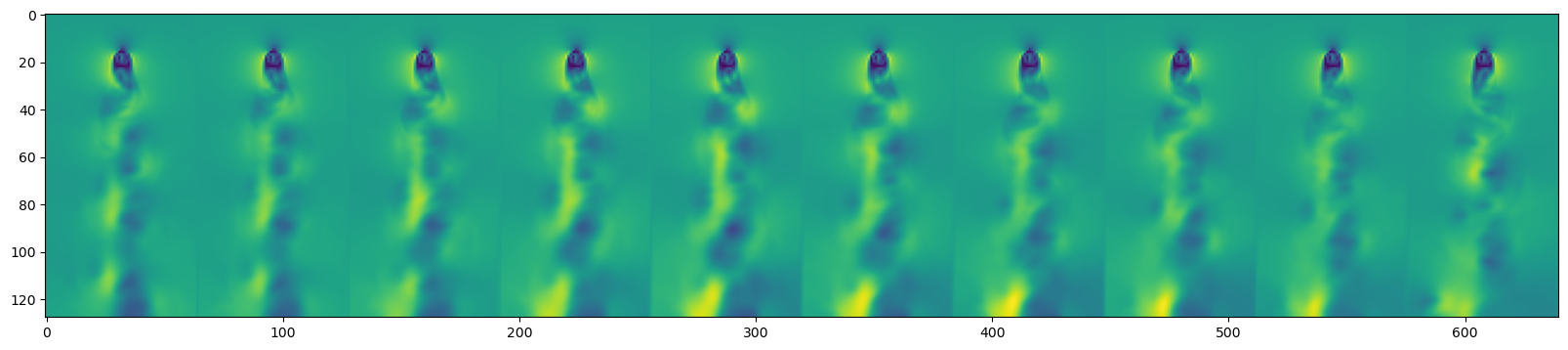
plt.figure(figsize=(20, 10))
plt.imshow(
np.hstack(y_test_pred[::3][-10:])
)
plt.figure(figsize=(20, 10))
plt.imshow(
np.hstack(dataset.y_test[::3][-10:])
)
plt.figure()
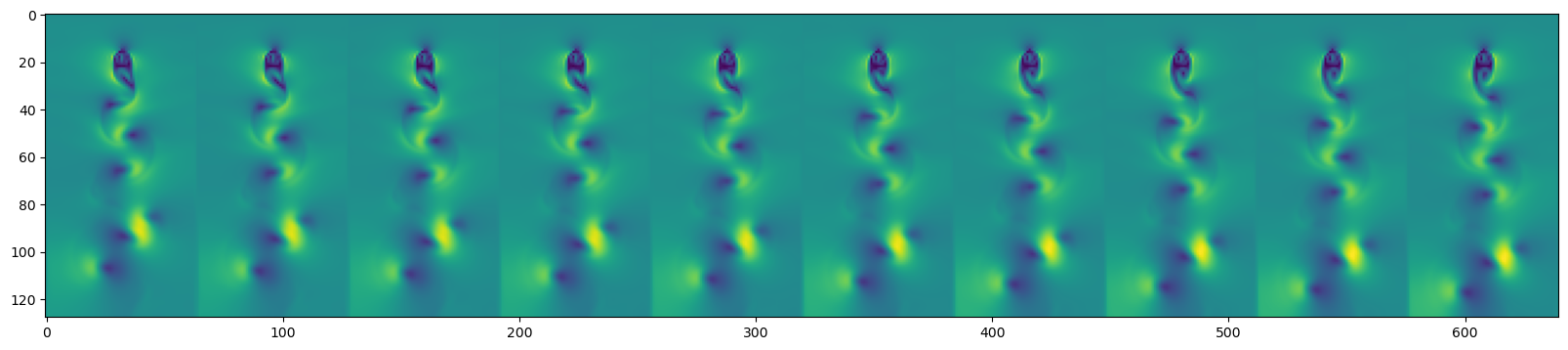
plt.plot(np.mean((y_test_pred - dataset.y_test)**2, axis=(1, 2)))
plt.ylabel("One step forecast error")
plt.xlabel("Time step")
Running with Instructor Solutions. If you meant to run your own code, do not import from solutions
Try some other regression models¶
Make sure you’ve installed scikit-learn in your local environment.
pip install scikit-learnThese models each have their own sets of hyperparameters. We will use the default values, but you will likely get better results by tuning them. Check out the scikit-learn documentation for more information about the different models.
from sklearn.neighbors import KNeighborsRegressor
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.neural_network import MLPRegressor
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import LinearRegression, Ridge, Lasso, ElasticNet
from sklearn.tree import DecisionTreeRegressor
## Package the data into a dataloader
dataset = ForecastingDataset(vfield_mag, featurizer=None)
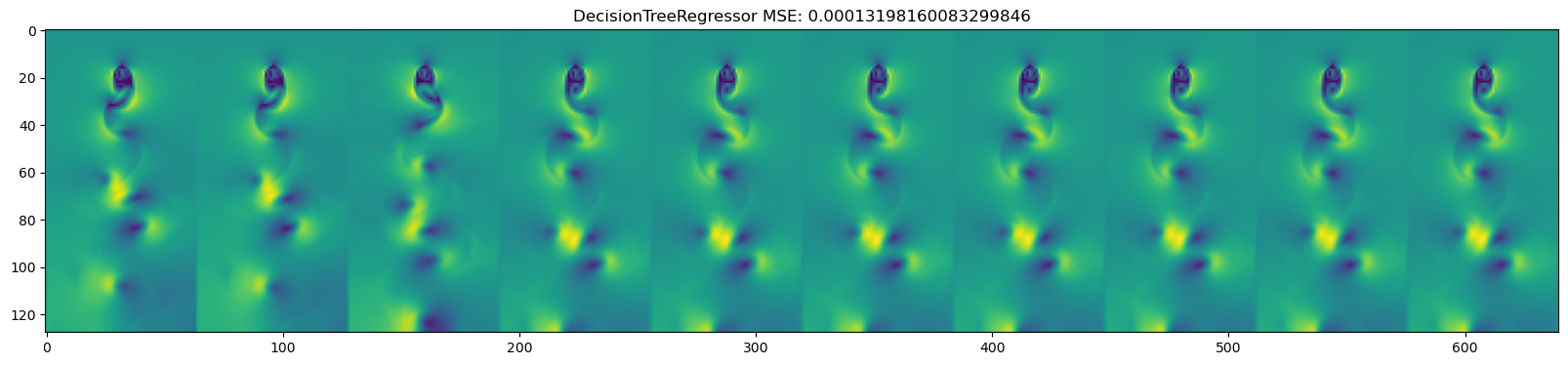
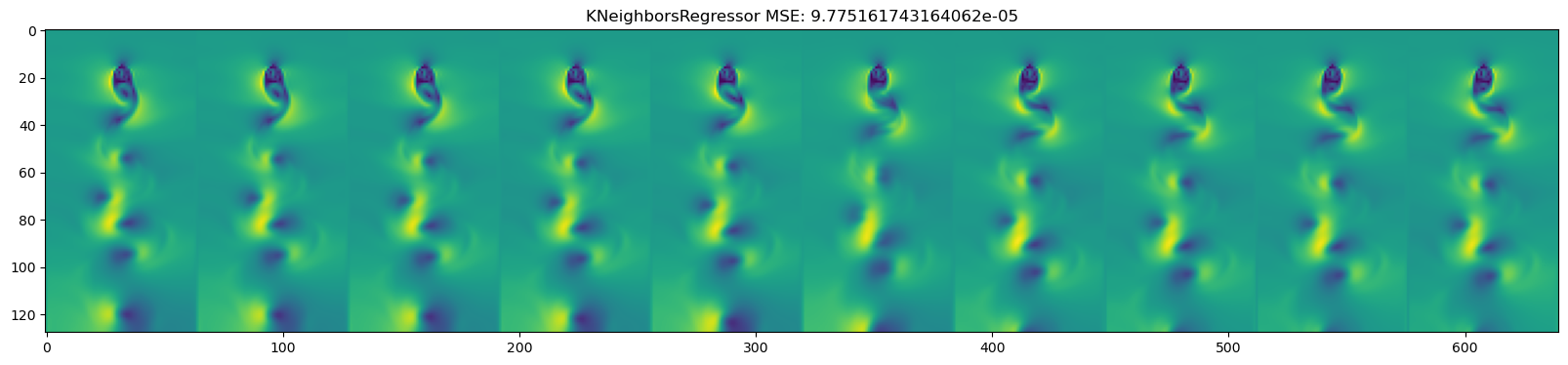
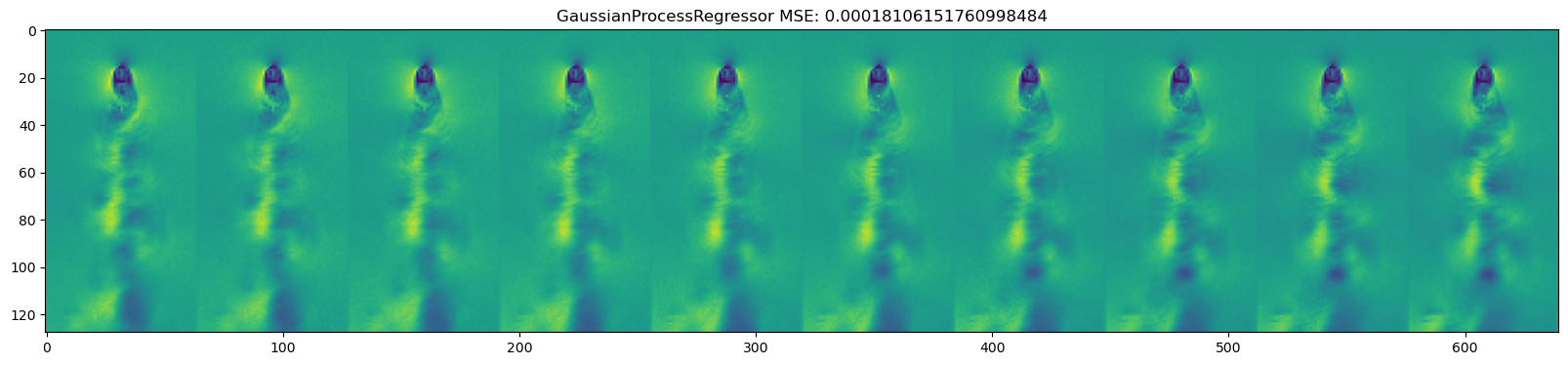
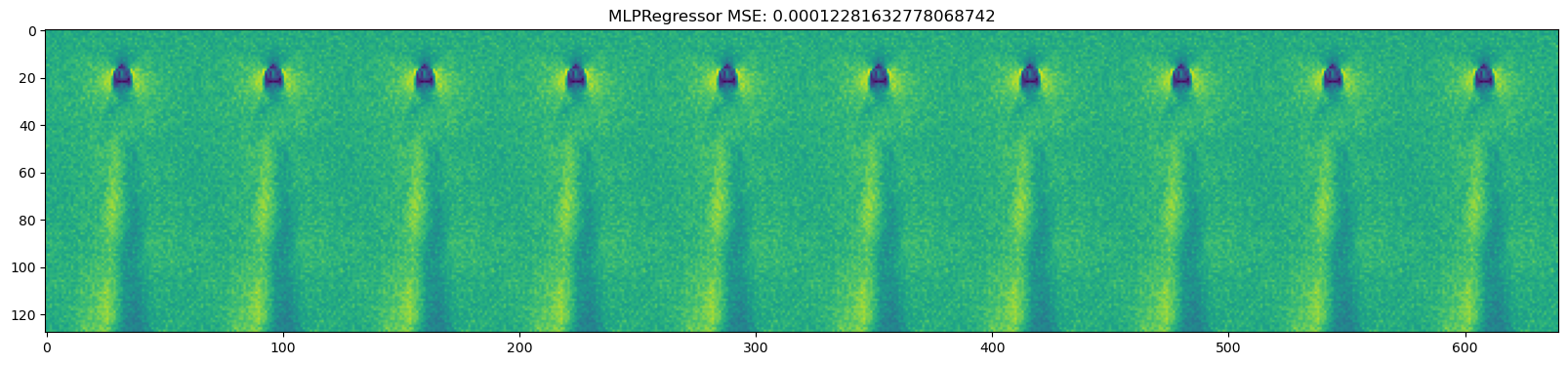
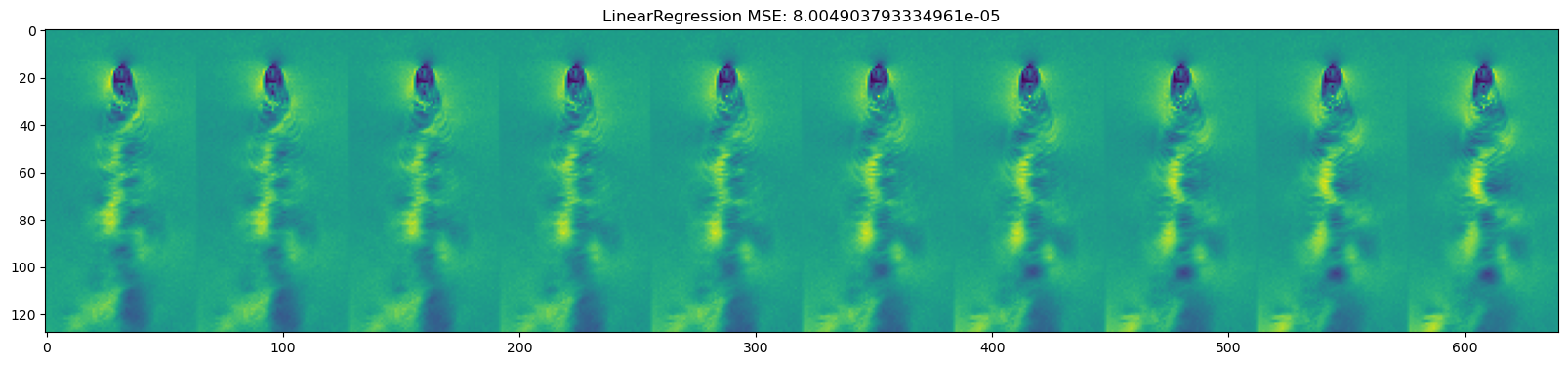
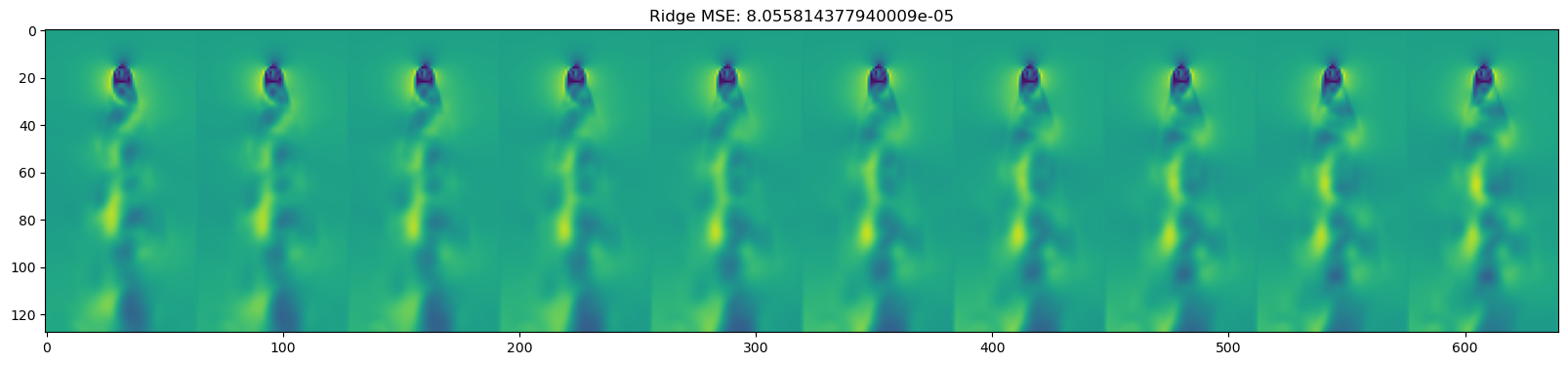
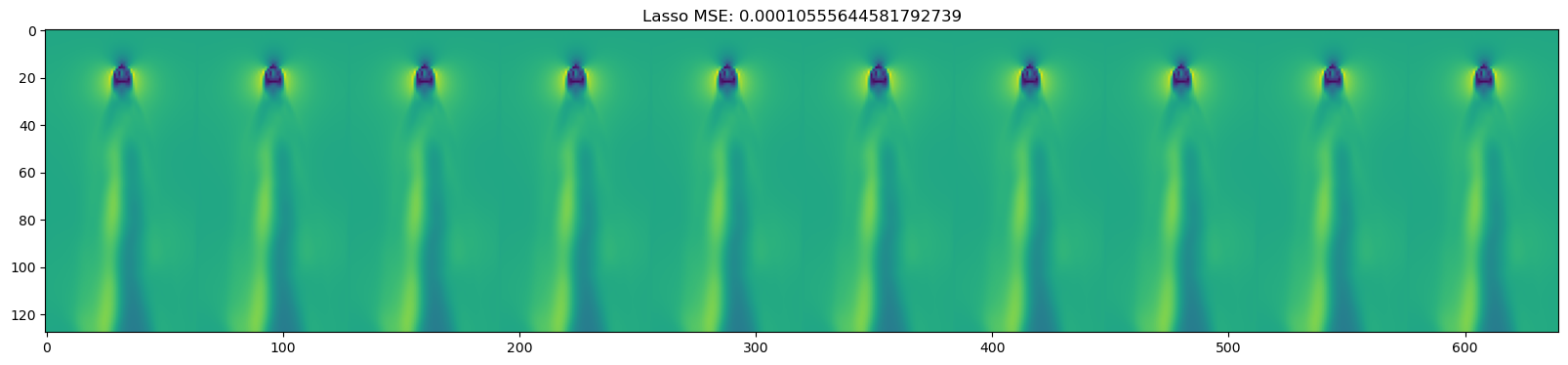
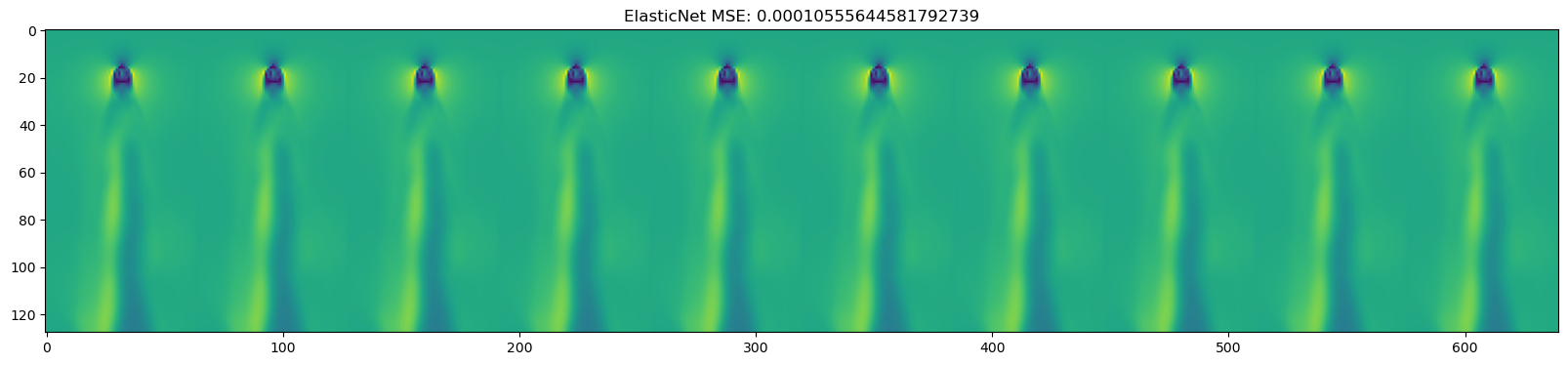
for model in [DecisionTreeRegressor(), KNeighborsRegressor(),
GaussianProcessRegressor(), MLPRegressor(),
LinearRegression(), Ridge(), Lasso(), ElasticNet()
]:
name = type(model).__name__
model.fit(
dataset.flatten_data(dataset.X_train),
dataset.flatten_data(dataset.y_train)
)
y_test_pred = dataset.unflatten_data(
model.predict(
dataset.flatten_data(dataset.X_test)
)
)
mse = np.mean((y_test_pred - dataset.y_test)**2)
plt.figure(figsize=(20, 10))
plt.imshow(np.hstack(y_test_pred[::3][-10:]))
plt.title(name + " " + f"MSE: {mse}")
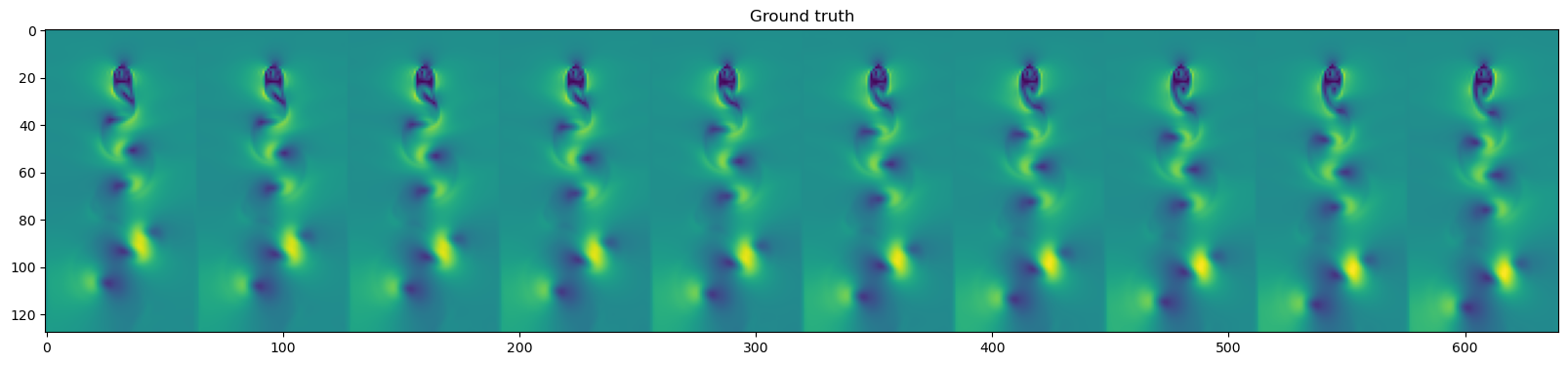
plt.figure(figsize=(20, 10))
plt.imshow(np.hstack(dataset.y_test[::3][-10:]))
plt.title("Ground truth")
Optional advanced problems¶
You’ll notice that we downsampled our velocity field data. That’s because the matrix operations needed to calculate the weight matrix become burdensome when the dataset is sufficiently large. Instead of directly solving our objective function with matrix algebra, we can instead iteratively solve it using gradient descent. Try implementing a gradient descent solution to the linear regression problem. For my version of the solution, I added a private method to the LinearRegressor object, and a keyword argument to the constructor that chooses between global and iterative solving.
If you want to even further improve your iterative method, try adding momentum and adaptive step size to your gradient descent. Here are some examples of common optimizers used to train machine learning models like neural networks
Advanced: Instead of the ridge penalty, we can use the Lasso, or L1, regularization term:
. This is a little bit trickier to implement than ridge regression, because the loss is not differentiable at 0.
A mathematical problem: We essentially fit a linear operator . Starting from the non-dimensional Navier-Stokes equations, derive an expression for the leading order linear behavior of the equations, as well as the first-order nonlinear term . How does accuracy of the linear approximation depend on the Reynolds number?
Additional information¶
Applications of deep learning to flow field modelling and prediction is an active area of research. Recent works propose physics-informed neural networks, where the same differentiability that faciliates gradient descent also allows calculation of gradient terms in the governing equations for the fluid flow.
Our ridge regression penalty represents a form of regularization, which helps prevent our model from overfitting. The ridge regularizer is commonly used even for more sophisticated models like deep neural networks, in order to constrain solutions to have simpler forms (even at the expense of overall accuracy). Many other regularizers exist, which serve to encourage certain desiderata in model space, such as representational uniqueness or sparsity.
Appendix: The Navier-Stokes equations¶
The Navier-Stokes equations comprise a set of partial differential equations describing the evolution of a velocity field ,
This equation describes several interacting phenomena. The first parenthetical term proportional to the local density corresponds to inertial forces, while the second term corresponds to pressure gradients in the fluid. The term proportional to the viscousity, , represents the effect of viscous drag within the fluid, while the forcing term corresponds to external forces.
We usually supplement this partial differential equation with an additional equation describing conservation of momentum,
Note that the full Navier-Stokes equations describe the dynamical evolution of three coupled fields: the velocity field , the local density , and the pressure . Usually, we will not attempt to directly solve the full equations, but instead we will first reduce these equations to a more specific form based on constraints or symmetries relevant to a specific problem. For example, when working with water or other liquids we usually assume the incompressibility condition , .
We will assume that we are working with an incompressible fluid with no body forces (). If our flow has a characteristic length scale and velocity scale , we can non-dimensionalize the Navier-Stokes equations by performing the substitution , , , , , producing the non-dimensionalized Navier-Stokes equations
where we have used the identities and
The non-dimensional Reynolds number is defined as . The Reynolds number quantifies the ratio of inertial to viscous forces in the system. At large , the advective terms dominate the Navier-Stokes equations, while the Laplacian term associated with dissipation vanishes. The resulting inertia-dominated equations, known as the Euler equation for ideal (frictionless) fluids, give rise to turbulence in fast-moving classical fluids at large length scales (the Euler equation also approximates the dynamics of superfluids, for similar reasons). At very small , however, friction dominates the system, leading to the Stokes equations. This overdamped dynamical regime describes many biological systems, and it many counterintuitive phenomena arise due to the appearance of time-reversal symmetry in the underlying equations.
- Raissi, M., Yazdani, A., & Karniadakis, G. E. (2020). Hidden fluid mechanics: Learning velocity and pressure fields from flow visualizations. Science, 367(6481), 1026–1030. 10.1126/science.aaw4741