LU Decomposition and the PageRank Algorithm¶
Preamble: Run the cells below to import the necessary Python packages
This notebook created by William Gilpin. Consult the course website for all content and GitHub repository for raw files and runnable online code.
import numpy as np
# Wipe all outputs from this notebook
from IPython.display import Image, clear_output, display
clear_output(True)
# Import local plotting functions and in-notebook display functions
import matplotlib.pyplot as plt
%matplotlib inline
Revisiting the coauthorship graph¶
- Coauthorship among physicists based arXiv postings in
astro-ph - The graph contains $N = 18772$ nodes, which correspond to unique authors observed over the period 1993 -- 2003
- If Author i and Author j coauthored a paper during that period, the nodes are connected
- In order to analyze this large graph, we will downsample it to a smaller graph with $N = 1000$ nodes representing the most highly-connected authors
- This dataset is from the Stanford SNAP database
import networkx as nx
## Load the full coauthorship network
fpath = "../resources/ca-AstroPh.txt.gz"
# fpath = "../resources/ca-CondMat.txt.gz"
g = nx.read_edgelist(fpath)
## Create a subgraph of the 1000 most well-connected authors
subgraph = sorted(g.degree, key=lambda x: x[1], reverse=True)[:4000]
subgraph = [x[0] for x in subgraph]
g2 = g.subgraph(subgraph)
# rename nodes to sequential integers as they would appear in an adjacency matrix
g2 = nx.convert_node_labels_to_integers(g2, first_label=0)
pos = nx.spring_layout(g2)
# pos = nx.kamada_kawai_layout(g2)
# nx.draw_spring(g2, pos=pos, node_size=10, node_color='black', edge_color='gray', width=0.5)
nx.draw(g2, pos=pos, node_size=5, node_color='black', edge_color='gray', width=0.5, alpha=0.5)
plt.show()


Estimating degree distributions, centrality, and the PageRank algorithm¶
We previously saw that the degree distribution determines how often a random walk on the graph will visit a given node. This can be seen an an indicator of how "important" a given node is to the structure of the graph. If we wanted to rank the authors purely based on their degree distribution, we could write this ranking as $$ \mathbf{R} = A \mathbb{1} $$ where $\mathbb{1} \in \mathbb{R}^N$ is a vector of ones, $A \in \mathbb{R}^{N\times N}$ is our adjacency matrix, and $\mathbf{R} \in \mathbb{R}^N$ is our desired ranking. Notice how the matrix product with the ones vector allows us to compute the rowwise sum. This makes sense, because we expect that this operation should take $N^2$ operations, and matrix-vector products are $N^2$.
A = nx.adjacency_matrix(g2).todense() # get the binary adjacency matrix of the graph
rank_degree = A @ np.ones(A.shape[0])
plt.figure(figsize=(7, 7))
nx.draw(g2, pos=pos, node_size=200, node_color=np.log10(rank_degree), edge_color='gray', width=0.01, cmap='viridis', alpha=0.2)
plt.title(f"Authors ranked by degree")
plt.show()
plt.figure(figsize=(7, 2))
plt.hist(rank_degree)
plt.ylabel("Number of Authors")
plt.xlabel("Degree")

Text(0.5, 0, 'Degree')

How else might we group authors?¶
The degree ranking simply tells use who the most well-connected authors are. They are the individuals who directly co-authored a paper with someone else at any point during the period over which the arXiv dataset was collected.
Recall that we can think of the degree distribution as the long-time limit of a random walker that "hops" among the neighboring nodes in a graph.
What if we add stochasticity? What if we allow the random walker to sometimes jump to any new node, not connected to the current node? This will cause the walker to explore the graph more broadly, and discover authors who are less connected to the dominant central cluster.
We will draw a loose analogy with the Ornstein-Uhlenbeck process. The spring constant pulls a random walker back to the origin, but the random noise allows the walker to explore the space more broadly. Likewise, the degree distribution pulls the random walker to the most connected nodes, but random jumps allow the walker to explore the graph more broadly.
This is the idea behind the PageRank algorithm, which is how Google originally ranked web pages. In Google's case, the entire internet is too large to know a priori the adjacency matrix of all web pages. Instead, they use a random walk algorithm to estimate the degree distribution of the web pages. Random hops allow the algorithm to more easily find smaller subnetworks, so that it doesn't keep revisiting dominant nodes like Wikipedia or Facebook.
Implementing the PageRank algorithm¶
We are now going to implement the PageRank algorithm on the coauthorship graph. The PageRank algorithm is a variant of the random walk algorithm that allows the random walker to sometimes jump to a new node with probability $1 - \alpha$.
If we interpret our desired ranking $\mathbf{R}$ as a probability distribution, then we can write a master equation describing the dynamics of the probability distribution of many random walkers. $$ \mathbf{R}_{t+1} = \alpha A \mathbf{R}_t + (1 - \alpha) \mathbb{1} $$ where $\mathbb{1} \in \mathbb{R}^N$ is a vector of ones, $A \in \mathbb{R}^{N \times N}$ is the adjacency matrix of the graph, and $\alpha$ is a parameter that controls the probability of the random surfer jumping to a random node. The first term on the right-hand side represents the process of the walker moving to a neighboring node, while the second term represents the process of jumping to a new node.
Solving this equation for the steady state distribution $\mathbf{R}_t = \mathbf{R}_{t+1}$ results in the PageRank equation $$ \mathbf{R} = \alpha A \mathbf{R} + (1 - \alpha) \mathbb{1} $$ This equation can be rewritten as an equation for $\mathbf{R}$, $$ \mathbf{R} = (1 - \alpha) (I - \alpha A)^{-1} \mathbb{1} $$
where $I$ is the identity matrix. We write these equations as a single matrix equation
$$ \mathbf{R} = \mathbf{M}^{-1} \mathbb{1} $$
where $\mathbf{M} \equiv (1 - \alpha) (I - \alpha A)$. If we set $\alpha = 1$ (no random jumps), then this equation becomes
$$ \mathbf{R} = \mathbf{M}^{-1} \mathbb{1} $$
alpha = 0.85 # a typical damping factor used in PageRank
M = (1 - alpha) * (np.eye(A.shape[0]) - alpha * A)
print(M.shape)
plt.imshow(M[:100, :100])
(4000, 4000)
<matplotlib.image.AxesImage at 0x17eb68890>

Inverting a matrix¶
We have taken for granted, so far, that we can invert a large matrix $\mathbf{A}$. Given a linear problem $$ A \mathbf{x} = \mathbf{b} $$ with $A \in \mathbb{R}^{N \times N}$, $\mathbf{x} \in \mathbb{R}^N$, and $\mathbf{b} \in \mathbb{R}^N$, we can solve for $\mathbf{x}$ by inverting $A$: $$ \mathbf{x} = A^{-1} \mathbf{b} $$
How would we do this by hand?¶
Gauss-Jordan elimination: perform a series of operations on both the left and the right hand sides of our equation (changing both $A$ and $\mathbf{b}$), until the left side of the equation is triangular in form. Because Gauss-Jordan elimination consists of a series of row-wise addition and subtraction operations, we can think of the process as writing each row vector in terms of some linear combination of row vectors, making the whole process expressible as a matrix $M$
$$ (M A) \mathbf{x} = M \mathbf{b} \\ $$ $$ U \mathbf{x} = M \mathbf{b} \\ $$ where we have defined the upper-triangular matrix $U \equiv MA$. This confirms our intuition that the time complexity of Gauss-Jordan elimination is $\sim\mathcal{O}(N^3)$, since that's the time complexity of multiplying two $N \times N$ matrices.
Why do we want triangular matrices?¶
If we can reduce our matrix $A$ to upper-triangular form, then we can quickly solve for $\mathbf{x}$ using forward substitution. This should take $\sim\mathcal{O(N^2)}$ operations if $A \in \mathbb{R}^{N \times N}$
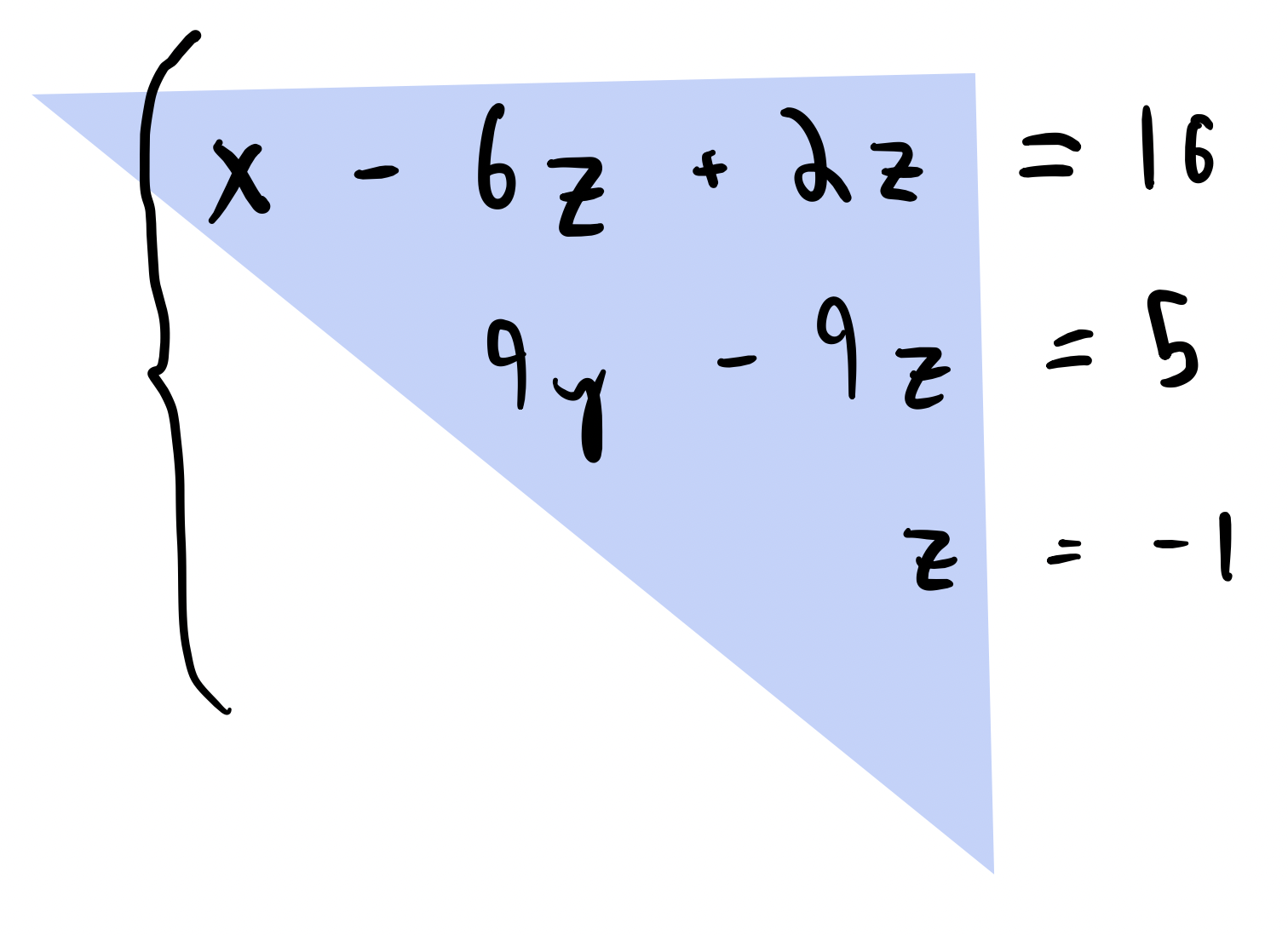
def solve_tril(a, b):
"""
Given a triangular matrix, solve using forward subtitution
Args:
a (np.ndarray): A lower triangular matrix
b (np.ndarray): A vector
Returns:
x (np.ndarray): The solution to the system
"""
#a = a.T # make it lower triangular for cleaner notation
n = a.shape[0]
x = np.zeros(n)
for i in range(n):
x[i] = (b[i] - np.dot(a[i, :i], x[:i])) / a[i, i]
return x
# A random lower triangular matrix
a = np.tril(np.random.random((10, 10)))
b = np.random.random(10)
print(np.linalg.solve(a, b))
print(solve_tril(a, b))
# Check that the numpy and our implementation give the same result
print(np.allclose(np.linalg.solve(a, b), solve_tril(a, b)))
# print(np.all(np.linalg.solve(a, b) == solve_tril(a, b)))
# np.sum(np.abs(np.linalg.solve(a, b) - solve_tril(a, b))) < 1e-14
[ 2.79707624 -2.18975392 53.23153183 -45.2687191 30.5757885 -655.20868552 537.77417227 188.26440703 -566.85239614 -94.10449712] [ 2.79707624 -2.18975392 53.23153183 -45.2687191 30.5757885 -655.20868552 537.77417227 188.26440703 -566.85239614 -94.10449712] True
import timeit
all_times1, all_times2 = list(), list()
nvals = np.arange(10, 500)
for n in nvals:
## Upper triangular solve
a = np.tril(np.random.random((n, n)))
b = np.random.random(n)
all_reps = [timeit.timeit("solve_tril(a, b)", globals=globals(), number=10) for _ in range(10)]
all_times1.append(np.mean(all_reps))
## Full solve
a = np.random.random((n, n))
b = np.random.random(n)
all_reps = [timeit.timeit("np.linalg.solve(a, b)", globals=globals(), number=10) for _ in range(10)]
all_times2.append(np.mean(all_reps))
plt.loglog(nvals, all_times1, label="Triangular solve")
plt.loglog(nvals, all_times2, label="Full solve")
plt.xlabel("Matrix size")
plt.ylabel("Time (s)")
plt.legend()
plt.show()

To invert a matrix, we just need to reach triangular form¶
We know that we want to modify our full matrix equation $$ A \mathbf{x} = \mathbf{b} $$ using a Gauss-Jordan elimination procedure, which we know has the form of a matrix multiplication $$ M A \mathbf{x} = M \mathbf{b} $$ We define $U \equiv M A$, and we know that we want to reduce $U$ to upper-triangular form. $$ U \mathbf{x} = M \mathbf{b} $$ But what is the form of $M$?
Our key insight is that the matrix $M$ turns out to be a triangular matrix as well.¶
Moreover, because the inverse of a triangular matrix is also a triangular matrix (this can be proven by writing out the terms in the matrix multiplication algebra for $U^{-1} U = I$), we therefore write a transformed version of our problem
$$ U \mathbf{x} = M \mathbf{b} $$ defining $M \equiv L^{-1}$, we arrive at the celebrated LU matrix factorization $$ L U \mathbf{x} = \mathbf{b} $$ where $L$ is a lower triangular matrix, and $U$ is an upper triangular matrix.
We can therefore solve for $\mathbf{x}$ by introducing an intermediate variable $\mathbf{h}$, and then $\mathbf{x}$ $$ LU \mathbf{x} = \mathbf{b} \\ L \mathbf{h} = \mathbf{b} \\ $$ where $\mathbf{h} \equiv U \mathbf{x}$.
If we can find the LU form, exactly solving the linear problem consists of the following steps:
- Solve the equation $\mathbf{h} = L^{-1} \mathbf{b}$. Since $L$ is a triangular matrix, this can be performed using substitution
- Solve the equation $\mathbf{x} = U^{-1} \mathbf{h}$. Since $U$ is also triangular, this is also fast
About LU factorization¶
Our iterative implementation uses Gauss-Jordan elimination in a principled order. We first eliminate the first column of the matrix, then the second column, and so on.
A more sophisticated algorithm called Crout's method with pivoting, which performs optimal order of decomposition based on the specific values present in a given row or column
Decomposition into L and U is $\sim \mathcal{O}(N^3)$ for an $N \times N$ matrix
Given a matrix $A$ and target $\mathbf{b}$, what is the overall runtime to find $\mathbf{x}$?
The LU decomposition algorithm¶
Set $L = I$ and $U = A$ (the input matrix)
For each column $j$ in $U$:
- Choose the pivot element $U_{jj}$ in the $j$th column
- For each row $i$ below the pivot:
- Find the multiplier $L_{ij} = U_{ij} / U_{jj}$
- Subtract $L_{ij} \times$ the $j$ th row from the $i$th row in $U$
- Store $L_{ij}$ in the $i$th row of $L$
In the context of the LU decomposition algorithm, the 'pivot' refers to the diagonal element in the current column, denoted as $U_{jj}$, that we are processing in the outer loop. The pivot serves as a divisor to find the multipliers $L_{ij}$ which are then used to eliminate the elements below the pivot, making them zero to carve out an upper triangular matrix $U$.
Simultaneously, these multipliers are stored in the lower triangular matrix $L$. Essentially, we are utilizing the pivot to find scalar values that can help perform row operations to systematically zero out elements below the diagonal in $U$, while building up the $L$ matrix.
We can see that there are three nested loops, which means that the time complexity of the LU decomposition algorithm is $\sim \mathcal{O}(N^3)$.
class LinearSolver:
"""
Solve a linear matrix equation via LU decomposition (naive algorithm)
"""
def __init__(self):
# Run a small test upon construction
self.test_lu()
def lu(self, a):
"""Perform LU factorization of a matrix"""
n = a.shape[0]
L, U = np.identity(n), np.copy(a)
for i in range(n):
factor = U[i+1:, i] / U[i, i]
L[i + 1:, i] = factor
U[i + 1:] -= factor[:, None] * U[i]
return L, U
# A unit test of a single class method
def test_lu(self):
"""A small test method that the factorization is correct"""
X = np.random.random((10, 10))
L, U = self.lu(X)
assert np.allclose(X, L @ U), "LU decomposition failed"
def forward_substitution(self, L, b):
"""Solve a lower triangular matrix equality of the form Lx = b for x"""
n = L.shape[0]
y = np.zeros(n)
y[0] = b[0] / L[0, 0]
for i in range(1, n):
y[i] = (b[i] - np.dot(L[i,:i], y[:i])) / L[i,i]
return y
def backward_substitution(self, U, b):
"""Solve an upper triangular matrix equality of teh form Ux = b for x"""
n = U.shape[0]
y = np.zeros(n)
y[-1] = b[-1] / U[-1, -1]
for i in range(n-2, -1, -1):
y[i] = (b[i] - np.dot(U[i,i+1:], y[i+1:])) / U[i,i]
return y
def solve(self, X, b):
L, U = self.lu(X)
self.L, self.U = L, U
# Intermediate variable
h = self.forward_substitution(L, b)
return self.backward_substitution(U, h)
A = np.random.rand(4, 4)
b = np.random.rand(4)
model = LinearSolver()
print(model.solve(A, b))
# Using the numpy built-in solver
print(np.linalg.solve(A, b))
print(np.allclose(model.solve(A, b), np.linalg.solve(A, b) ))
[ 1.13327806 -1.41619997 0.5899517 0.65301225] [ 1.13327806 -1.41619997 0.5899517 0.65301225] True
Applying LU Decomposition of orthogonal basis sets
A Hadamard matrix is a square matrix comprising a complete collection of length $N$ mutually-orthogonal vectors with all elements equal to either $+1$ or $-1$
We can convert any complete orthonormal basis to a Hadamard matrix by ordering the vectors systematically, and substituting $0$ and $1$ for $\pm 1$ with a recursive rule
def hadamard(n):
"""
Create a Hadamard matrix of size n
"""
if n == 1:
return np.array([[1]])
else:
H = hadamard(n // 2)
return np.block([[H, H], [H, -H]])
plt.figure(figsize=(10, 10))
a = hadamard(2**8).astype(float)
plt.imshow(a, cmap='gray')
plt.axis('off')
(-0.5, 255.5, 255.5, -0.5)

ll, uu = model.lu(a)
plt.figure(figsize=(9, 4.5))
plt.subplot(121)
plt.imshow(ll, cmap='gray')
plt.axis('off')
plt.subplot(122)
plt.imshow(uu.astype(bool), cmap='gray')
plt.axis('off')
## show plots closer together
plt.subplots_adjust(wspace=0.1)

Applying PageRank to the coauthorship graph¶
We can now apply the PageRank algorithm to the coauthorship graph.
A = nx.adjacency_matrix(g2).todense() # get the binary adjacency matrix of the graph
def find_pagerank(A, alpha=0.85, verbose=False):
"""
Find the PageRank of a graph using matrix inversion
Args:
A (np.ndarray): The adjacency matrix of the graph
alpha (float): The damping factor. The default value is 0.85
Returns:
page_rank (np.ndarray): The PageRank of each node
"""
M = (1 - alpha) * (np.eye(A.shape[0]) - alpha * A)
if verbose:
print(f"Condition number of M: {np.linalg.cond(M)}", flush=True)
## use our LU solver to solve for the PageRank
# page_rank = np.linalg.inv(M) @ np.ones(M.shape[0])
l, u = LinearSolver().lu(M)
Minv = np.linalg.inv(u) @ np.linalg.inv(l)
page_rank = Minv @ np.ones(M.shape[0])
return page_rank
plt.figure(figsize=(8, 8))
nx.draw(g2, pos=pos, node_size=200, node_color=np.log10(rank_degree),
edge_color='gray', width=0.02, cmap='viridis', alpha=0.2)
plt.title(f"Degree Ranking")
plt.show()
page_rank1 = find_pagerank(A, alpha=0.05, verbose=True)
plt.figure(figsize=(8, 8))
nx.draw(g2, pos=pos, node_size=200, node_color=np.log10(page_rank1),
edge_color='gray', width=0.02, cmap='viridis', alpha=0.2)
plt.title(f"PageRank centrality with alpha=0.05")
plt.show()
page_rank2 = find_pagerank(A, alpha=0.99, verbose=True)
plt.figure(figsize=(8, 8))
nx.draw(g2, pos=pos, node_size=200, node_color=np.log10(page_rank2),
edge_color='gray', width=0.02, cmap='viridis', alpha=0.2)
plt.title(f"PageRank centrality with alpha=0.95")
plt.show()

Condition number of M: 3808.383285542044
/var/folders/xt/9wdl4pmx26gf_qytq8_d528c0000gq/T/ipykernel_30515/3448364456.py:36: RuntimeWarning: invalid value encountered in log10 nx.draw(g2, pos=pos, node_size=200, node_color=np.log10(page_rank1),

Condition number of M: 112286.22458188192
/var/folders/xt/9wdl4pmx26gf_qytq8_d528c0000gq/T/ipykernel_30515/3448364456.py:44: RuntimeWarning: invalid value encountered in log10 nx.draw(g2, pos=pos, node_size=200, node_color=np.log10(page_rank2),

We can see that high values of $\alpha$ cause the PageRank algorithm to look more like the degree distribution. This emphasizes larger subnetworks and and more highly-connected nodes. Conversely, low values of $\alpha$ cause the PageRank algorithm to converge to somether closer to a uniform distribution.